Memory and context poisoning: Don't let attackers rewrite your AI agent's memory
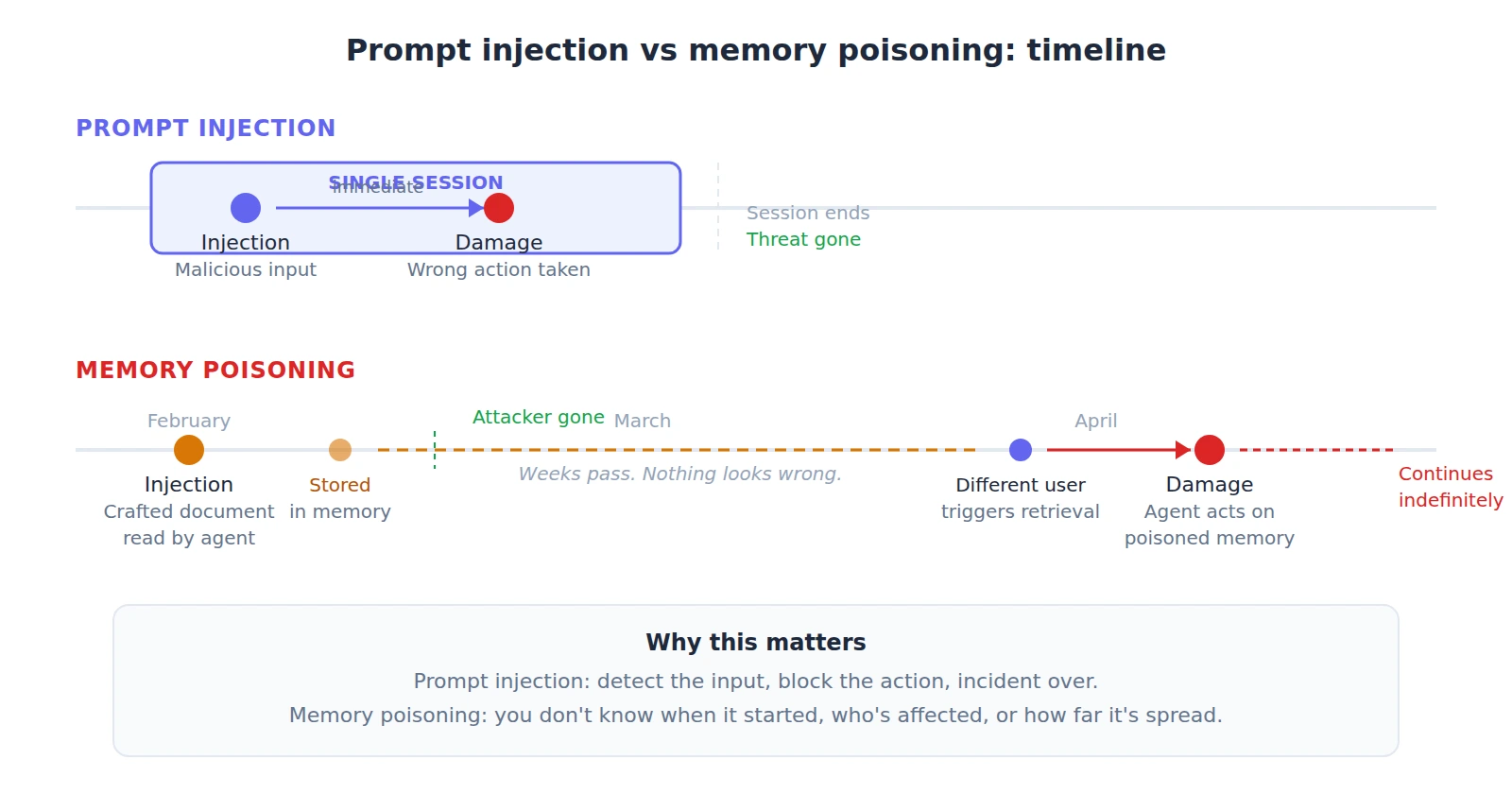
Prompt injection ends when the session closes. Memory poisoning persists across sessions, activates weeks later, and is nearly invisible to detect.
In December 2025, researchers published MemoryGraft, an attack that compromises AI agents by planting malicious entries in their long-term memory through benign-looking content. A README file in a code repository. A document in a shared folder. The agent reads it, stores a summary in its memory, and moves on. Weeks later, when the agent encounters a similar task, it retrieves the poisoned "successful experience" and imitates the malicious pattern, believing it's following its own proven playbook.
The same month, the MINJA attack was presented at NeurIPS 2025. It demonstrated something worse: an attacker can poison an agent's memory through nothing more than normal queries. No direct access to the memory store. No elevated privileges. Just carefully crafted interactions that the agent processes normally but which corrupt its memory as a side effect. MINJA achieved over 95% injection success rates against production agent architectures.
This is ASI06 from the OWASP Top 10 for Agentic Applications: memory and context poisoning. It's the risk that separates agentic security from chatbot security. A chatbot has no memory. Each session starts clean. An agent that uses persistent memory, whether that's a vector store, a RAG knowledge base, a conversation summary, or a facts database, carries its past into every future session. If that past has been tampered with, every future decision is compromised.
The previous articles in this series built defenses for the agent's runtime: scoped credentials, supply chain verification, invocation policy, prompt injection containment, and delegation security. Those controls assume the agent's context is trustworthy. This article covers what happens when it isn't.
Why memory poisoning is different from prompt injection
The difference is not just persistence. It's the entire threat model.
- Temporal decoupling. In a prompt injection attack, the injection and the damage happen in the same session. In a memory poisoning attack, they can be separated by weeks or months. The attacker crafts a malicious input in February. The agent stores a poisoned memory. In April, a completely different user triggers a task that retrieves the poisoned memory, and the agent acts on it. The attacker is long gone. The victim never interacted with the malicious content directly. Your monitoring sees nothing suspicious at any single point in time because the attack spans two events that look normal in isolation.
- Implicit trust. An agent treats its own memories as ground truth. There's a meaningful difference between how an agent processes external input ("the user says X") and how it processes retrieved memory ("I know X from past experience"). External input gets some skepticism. Memory gets none. This makes poisoned memories more influential than direct injection, because they bypass whatever input-level defenses you've built.
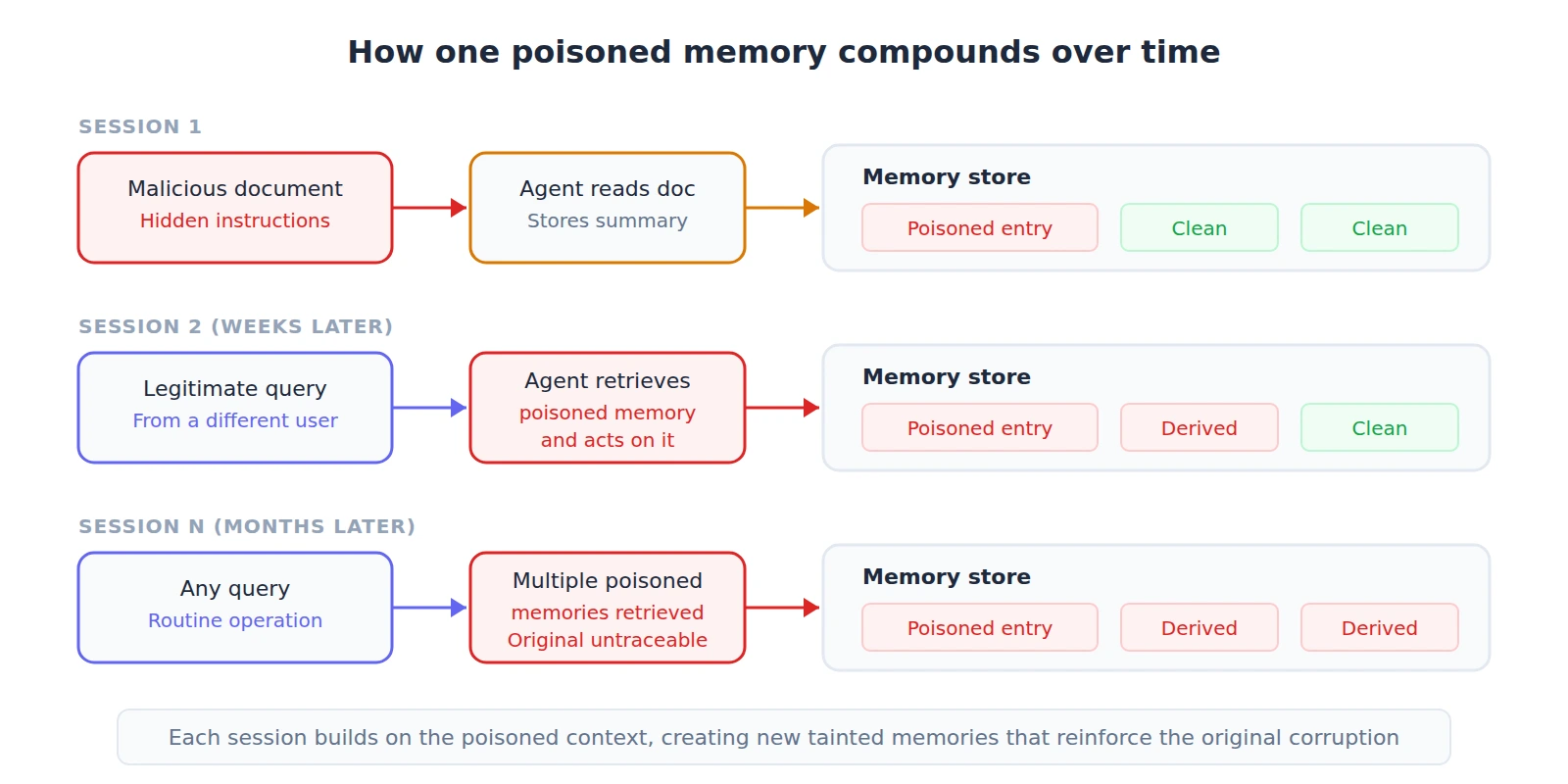
- Compounding effect. A poisoned memory doesn't just affect one decision. It affects every future decision where that memory is retrieved. And each decision the agent makes based on poisoned memory can itself generate new memories, further contaminating the store. Over time, the agent's internal context drifts further from reality, and the original poisoned entry becomes harder to identify because it's surrounded by legitimate-looking memories that built on it.
- Detection difficulty. Prompt injection produces anomalous behavior immediately: the agent does something unexpected in response to a specific input. Memory poisoning produces subtle behavioral drift over time. The agent doesn't suddenly do something wrong. It gradually shifts its decision patterns in ways that look plausible in isolation. Traditional monitoring that watches for anomalous single events will miss it.
The attack surface: four entry points
Attackers can poison an agent's memory through four primary entry points, each targeting a different component of the agent's context infrastructure.
RAG knowledge base corruption
Retrieval-augmented generation systems pull documents from a vector database before generating a response. If the attacker can influence any document in the retrieval corpus, they can inject content the agent will treat as authoritative context. PoisonedRAG, presented at USENIX Security 2025, demonstrated that inserting a small number of crafted documents into the retrieval corpus can cause the RAG system to reliably return attacker-chosen answers for specific queries.
The entry points for RAG poisoning include web pages the agent indexes, documents uploaded to shared repositories, emails that get ingested into knowledge bases, and public data sources the system crawls. Any content pipeline that feeds your vector store is a potential injection path.
Long-term memory manipulation
Agents that maintain persistent memory (facts databases, preference stores, decision histories) are vulnerable to MINJA-style attacks that corrupt memory through normal interaction. The attacker sends queries that look legitimate but are designed to cause the agent to store specific malicious entries. Because the entries are created through the agent's own memory mechanisms, they're indistinguishable from legitimate memories.
Conversation summary poisoning
Many agent frameworks compress long conversations into summaries that persist across sessions. If the attacker can manipulate the content of a conversation before it's summarized, the summary inherits the manipulation. The agent then uses the poisoned summary as context for future sessions, treating it as a reliable record of what happened.
Cross-agent contamination
In multi-agent systems where agents share knowledge bases or memory stores, a single compromised agent can poison the entire system. Agent A stores a malicious memory. Agent B retrieves it during a routine task. Agent B's output, now influenced by the poisoned memory, gets stored as a new memory entry. The contamination spreads through normal collaborative operations without any agent detecting anything wrong.
This connects directly to the delegation security covered in the previous article. Shared memory stores between agents are a delegation boundary that needs the same validation and scoping controls as inter-agent messages.
Defending the memory layer
Memory poisoning can't be solved with a single control. Like the other risks in this series, it requires defense in depth: multiple layers that each catch different attack patterns.
Validate at ingestion
Every piece of content entering the memory store should be validated before it's stored. This is the memory equivalent of argument validation at the tool invocation boundary.
The key principle is that not all memories are equally trustworthy. A memory derived from a verified internal document should carry more weight than one derived from an external web page. Assigning trust scores at ingestion time means the retrieval system can prioritize high-trust memories and deprioritize or exclude low-trust ones.
Track provenance
Every memory entry should record where it came from, when it was created, and what content it was derived from. This is the memory equivalent of the audit trail described throughout this series.
Provenance tracking serves two purposes. During normal operation, it enables trust-aware retrieval: the agent can weight memories by their provenance when deciding how much to rely on them. During incident response, it enables forensics: when you discover a poisoned memory, you can trace it back to its origin and identify every downstream memory and decision it influenced.
Isolate memory by scope
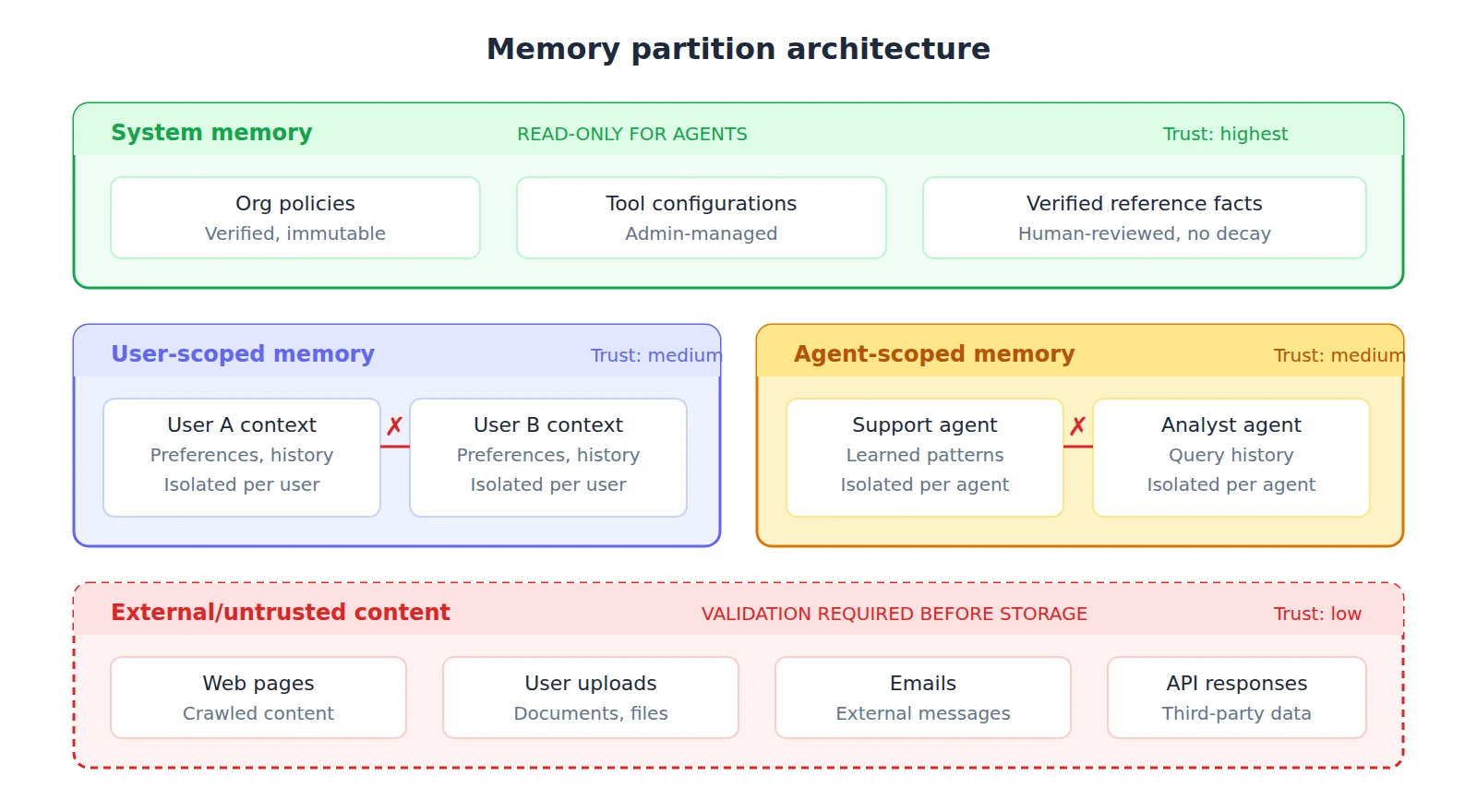
Don't put everything in one store. Partition memory by trust level, agent identity, and purpose:
- System memories (tool configurations, organizational policies, verified facts) should be stored in a read-only partition that agents can query but never modify. Changes to system memory require human review.
- User-scoped memories (preferences, conversation history, task context) should be isolated per user. Agent A's memories about User X should not be accessible when Agent A is working with User Y. This prevents a poisoned memory from one user's session from affecting another user's experience.
- Agent-scoped memories (learned behaviors, task patterns, operational context) should be isolated per agent. In multi-agent systems, this prevents cross-agent contamination. If Agent A's memory is poisoned, Agent B's isolated memory store is unaffected.
Set expiration policies
Memories should decay. A memory from six months ago that hasn't been accessed or validated should carry less weight than a memory from last week. Implementing temporal decay reduces the window during which a poisoned memory can influence agent behavior.
Critical memories (verified policies, core configurations) should be exempt from decay and stored in the read-only system partition. Everything else should lose influence over time unless it's periodically revalidated.
Monitor for behavioral drift
Memory poisoning produces gradual changes in agent behavior, not sudden ones. Your monitoring needs to detect drift, not just anomalies.
Track the distribution of memory sources the agent retrieves over time. If the agent starts pulling from low-trust sources more frequently, or if a cluster of new memories from a single external source starts dominating retrieval results, that's a signal worth investigating.
Track decision patterns. If the agent's recommendations or actions shift in a consistent direction over a period of weeks, compare the shift against the memories that were added during that period. Correlation between new memories and behavioral change is the primary signal for detecting poisoning.
This is the hardest defense to implement because it requires establishing a behavioral baseline before you can detect deviations from it. Start by logging retrieval patterns and decision outcomes for several weeks before turning on drift detection. The baseline needs to reflect normal variability, not just a single snapshot.
Incident response: when you find poisoned memories
When you detect or suspect memory poisoning, the response process is different from other security incidents because of the temporal decoupling problem. You're not just cleaning up damage from today. You're tracing influence that may have started weeks or months ago.
- Identify the poisoned entries. Use provenance tracking to find memories with suspicious origins (low-trust sources, unusual creation patterns, contradictions with established facts).
- Trace downstream influence. Every memory that was derived from or influenced by the poisoned entry is potentially contaminated. The
derivedFromfield in your provenance records lets you build this dependency graph. - Quarantine, don't delete. Move suspected entries to a quarantine partition rather than deleting them. You need them for forensic analysis and to understand the full scope of the compromise.
- Audit decisions made during the exposure window. Between the time the poisoned memory was stored and the time it was quarantined, every decision that retrieved that memory is suspect. Review them against the audit trail from the rest of the series.
- Revalidate the remaining store. Run consistency checks across the memory store to identify other entries that may have been poisoned through the same vector but weren't caught by the initial detection.
Securing AI agents and MCP servers with WorkOS
Memory poisoning is a context-layer attack, but its blast radius is bounded by the same identity and authorization controls described throughout this series. An agent with scoped credentials can only access memories within its authorized partition. FGA enforces resource boundaries that prevent cross-tenant memory contamination. Audit logging captures every memory retrieval and tool invocation, giving you the forensic trail you need when poisoning is detected. WorkOS provides that infrastructure: OAuth 2.1 for agent credentials, FGA for resource-scoped access control, audit logging, and native MCP server authentication.