AI agents are taking over: How autonomous software changes research and work
Interest in AI agents is exploding, and they're already transforming how we work and perform research. Learn how.
When researching a new topic, your first instinct might be to run a Google search.
You type in a query, scan through lists of links, and sift through articles to extract what’s important.
An AI agent, by contrast, autonomously locates relevant sources, filters and interprets the data, and then presents a structured summary, directly giving you insight.
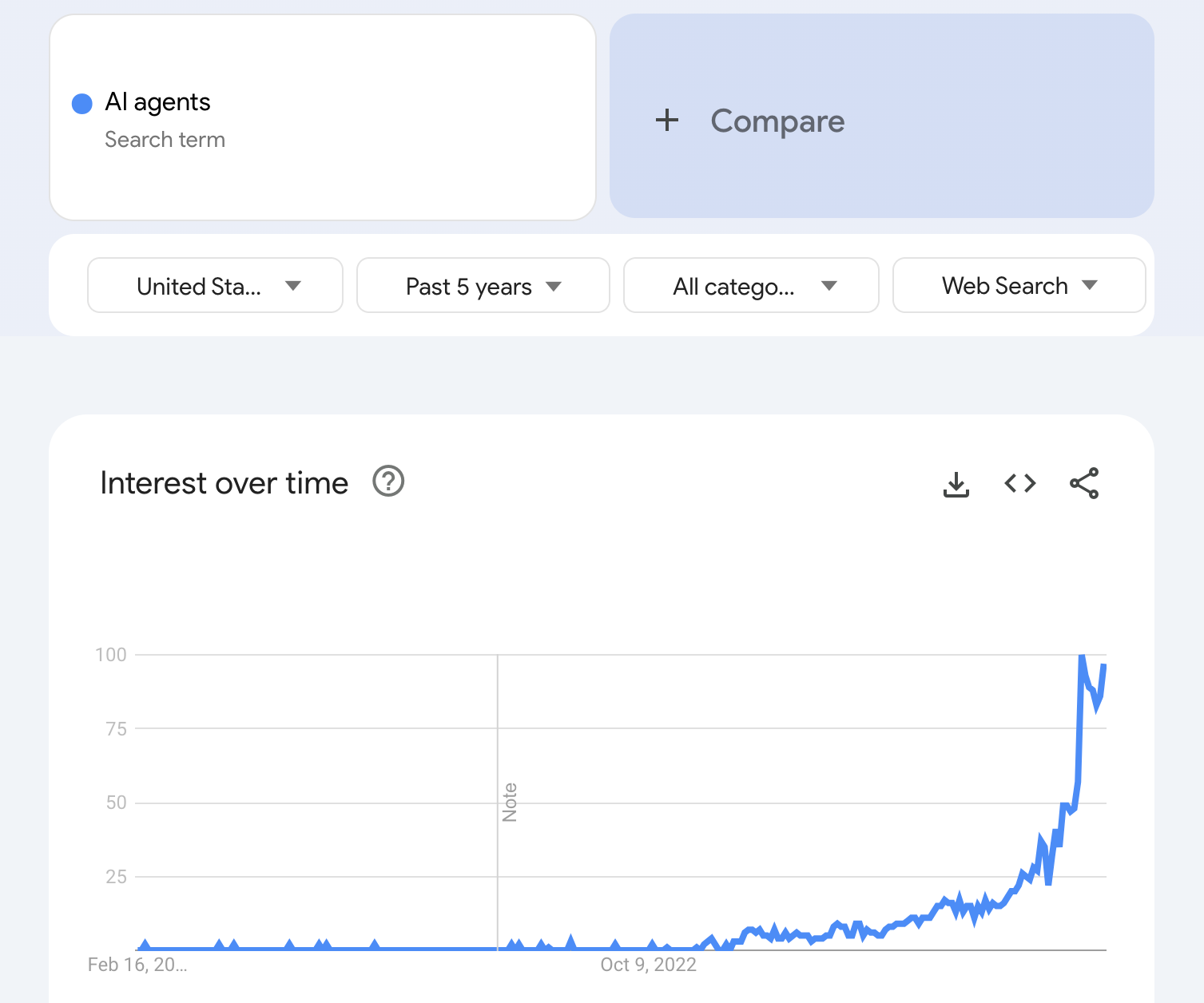
There’s a reason that interest in AI agents is currently exploding.
Traditional software vs. autonomous agents
Traditional, non-agentic software typically functions in a static, user-driven manner.
Users must trigger every action—click here, select there—and once the software provides the data, it’s up to the user to synthesize. AI agents take a more proactive approach.
Rather than waiting for the user to issue every command, they decide what data to fetch and how to process it to meet specific goals.
By delivering structured, summarized results, they reduce users' cognitive load and transform research from a multi-step manual process into a hands-off experience.
Key characteristics of AI agents
What characteristics separate true AI agents from intelligent scripts or sophisticated traditional software?
- Autonomy – AI agents operate independently, reducing the need for human intervention.
- Perception and data gathering – Agents collect data from APIs, databases, user input, or real-world sensors.
- Decision-making – Using predefined logic, machine learning, or reinforcement learning, agents determine the next best action.
- Action execution – Agents interact with systems (e.g., sending API requests, updating databases, or modifying user interfaces).
- Adaptability – Some agents improve over time through learning or feedback loops.
Automation scripts and traditional software execute predefined steps but do not adapt based on context, but AI-powered agents dynamically adjust their actions based on real-time data and decision models.
Types of AI agents
- Reactive agents – Respond to inputs without memory or learning (e.g., rule-based chatbots).
- Deliberative agents – Use internal models to plan before acting (e.g., AI-powered personal assistants).
- Learning agents – Improve over time via reinforcement learning or fine-tuning (e.g., self-improving recommendation systems).
- Multi-agent systems – Multiple AI agents working together to achieve complex goals (e.g., autonomous trading bots coordinating transactions).
How a research agent works
An AI agent can replace days of opening multiple browser tabs and skimming content with an automated cycle:
- Fetch: It searches relevant online repositories or APIs to locate the information you need—like research papers or articles.
- Analyze: It then interprets each source, extracting key points or summarizing entire texts.
- Deliver: Instead of a generic list of links, the agent provides a coherent synthesis of its findings.
A traditional search engine might show you where to look; an AI agent tells you what you need to know.
| Feature | Search engine | AI Agent |
|---|---|---|
| Fetches Information | Returns links | Gathers and summarizes |
| Processes Content | User manually reads | AI extracts key points |
| Reduces Workload | No | Yes |
| Delivers Structured Insights | No | Yes |
Example: a JavaScript research agent
Below is an example of a JavaScript-based research agent that autonomously fetches research papers from the Semantic Scholar API and summarizes them using the OpenAI API.
You can adapt or expand on this code for different data sources and summarization techniques.
class EnhancedResearchAgent {
constructor(userGoal, initialQuery) {
this.userGoal = userGoal;
this.currentQuery = initialQuery;
this.results = [];
this.iteration = 0;
this.maxIterations = 3; // Limit how many times we refine the query
}
// Decide on next steps (e.g., refine the query if we haven't met the goal)
plan() {
this.iteration++;
console.log(`\n[Plan] Iteration ${this.iteration}: Current query: "${this.currentQuery}"`);
// In a real agent, you might use GPT or other logic to decide how to refine the query
// based on prior search results, user feedback, or missing information.
}
async fetchResearchPapers() {
console.log("[Gather] Fetching research papers...");
try {
const response = await fetch(
`https://api.semanticscholar.org/graph/v1/paper/search?query=${encodeURIComponent(this.currentQuery)}&limit=3`
);
if (!response.ok) {
throw new Error(`Semantic Scholar API error: ${response.status}`);
}
const data = await response.json();
// Save minimal info for each paper
this.results = data.data.map(paper => ({
title: paper.title,
paperId: paper.paperId,
url: `https://www.semanticscholar.org/paper/${paper.paperId}`
}));
} catch (error) {
console.error('Error fetching research papers:', error);
}
}
// Summarize a single paper title or abstract
async generateSummary(text) {
try {
const response = await fetch("https://api.openai.com/v1/chat/completions", {
method: "POST",
headers: {
"Content-Type": "application/json",
"Authorization": `Bearer YOUR_OPENAI_API_KEY`
},
body: JSON.stringify({
model: "gpt-4o",
messages: [{ role: "user", content: `Summarize this: ${text}` }]
})
});
if (!response.ok) {
throw new Error(`OpenAI API error: ${response.status}`);
}
const data = await response.json();
return data.choices[0].message.content;
} catch (error) {
console.error('Error generating summary:', error);
return 'Summary unavailable';
}
}
// Summarize all results, in parallel where possible
async analyzeResults() {
console.log("[Analyze] Summarizing fetched papers...");
await Promise.all(this.results.map(async (paper) => {
paper.summary = await this.generateSummary(paper.title);
}));
}
// Simple placeholder to check if the results match the user goal
// Real-world usage might use embeddings, more advanced NLP, user feedback, etc.
checkRelevance() {
if (!this.results.length) return false;
// Trivial check: if the userGoal appears in the paper title or summary, call it "relevant"
const relevantCount = this.results.filter(paper =>
(paper.title && paper.title.toLowerCase().includes(this.userGoal.toLowerCase())) ||
(paper.summary && paper.summary.toLowerCase().includes(this.userGoal.toLowerCase()))
).length;
// Decide a threshold for "good enough"
return relevantCount > 0;
}
// Decide whether to refine the query based on current results
refineQueryIfNeeded() {
const isRelevant = this.checkRelevance();
if (isRelevant) {
console.log("[Evaluate] Enough relevant papers found. Stopping here.");
return true;
} else if (this.iteration < this.maxIterations) {
// Naive refinement example: add more terms or synonyms
console.log("[Evaluate] Results not relevant enough. Refining query...");
this.currentQuery += " advanced techniques";
return false;
} else {
console.log("[Evaluate] Max iterations reached. Stopping anyway.");
return true;
}
}
// Main loop
async run() {
let done = false;
while (!done && this.iteration < this.maxIterations) {
this.plan();
await this.fetchResearchPapers();
if (this.results.length === 0) {
// If no papers were fetched, refine or break
done = this.refineQueryIfNeeded();
continue;
}
await this.analyzeResults();
done = this.refineQueryIfNeeded();
}
return this.results;
}
}
// Example usage
(async () => {
// Goal: find relevant reinforcement learning papers
const agent = new EnhancedResearchAgent("reinforcement learning", "reinforcement learning");
const finalResults = await agent.run();
console.log("\nFinal agent results:", finalResults);
})();- Iteration & planning: Each run has a plan step (plan()), which could be replaced by more advanced reasoning (e.g., GPT-based chain-of-thought, user feedback).
- Refinement: If the fetched results aren’t deemed relevant, the agent automatically updates its query to try again.
- Decision logic: The agent decides when to stop based on relevance checks or iteration limits. In a real system, you’d replace the checkRelevance() logic with more sophisticated embeddings or feedback loops.
This is an example of a self-directed AI agent—one that can perceive (fetch), analyze (summarize), and act (refine queries or stop) rather than just running a single fetch-and-summarize step.
Advantages of AI agents and considerations
One of the biggest advantages AI agents offer is time efficiency. By automating data gathering and analysis, they free users from the repetitive chore of reading through and synthesizing raw information.
The insights they provide are both actionable and scalable—once set up, it’s straightforward to incorporate additional features like Wikipedia lookups, patent searches, or integration with communication tools such as email or Slack.
However, deploying AI agents also raises important considerations:
- Quality of summaries: The value of AI-generated insights depends heavily on the quality and relevance of both the source data and the underlying model.
- Ethical implications: As agents become more autonomous, designers must address transparency, bias, and privacy concerns.
- Error handling and reliability: A robust error management system is essential, especially for agents relying on multiple external APIs.
- Integration challenges: Combining various data sources often involves dealing with authentication, rate limits, and data consistency requirements.
Future improvements for autonomous software
AI agents are poised to change how we interact with information. Possible next steps and likely patterns include:
- Real-time UI integration: Expect to see more frontends that display live results and capture user feedback to refine the agent’s outputs.
- Enhanced data sources: Expand beyond Semantic Scholar into Wikipedia, ArXiv, patent databases, and domain-specific APIs. Expect to see source-specific agents, marketplaces, and ecosystems for agentic tools and functionality.
- Relevance ranking: The use of embeddings or other ranking strategies to filter and order results based on the user’s specific context or intent.
- Multi-agent collaboration: Explore scenarios in which multiple specialized agents coordinate to tackle complex or interdisciplinary research questions.
AI agents represent a step change from traditional software models, allowing you to focus on making decisions rather than gathering information.
By autonomously fetching, interpreting, and synthesizing data, these agents significantly reduce the manual labor involved in research.