Clearing up (my own) OAuth misunderstandings
Why OAuth works the way it does: authorization codes, token expiry, and PKCE explained from first principles.
I vaguely understood OAuth before joining WorkOS, but now is time to solidify my understanding. I'll share the low level of understanding I had, and what I learned recently about some design choices of OAuth.
OAuth is an authorization protocol whereby a user, via an authorization server, grants a 3rd party application (called the "client") access to resources hosted on a resource server.
The main OAuth dance I know goes something like this:
- Client application prompts user to grant access to a resource
- User is redirected to an authorization server where they identify themselves and grant a set of access rights (the "scope" of authorization)
- User is redirected to a callback url on the client application, with an authorization code
- The authorization code is exchanged on back channels between the client application and the authorization server to get an access token, and maybe a refresh token
- The client application uses the access token with the resource server to access the user resource in accordance with the scope
- The access token expires
- The client application uses the refresh token to acquire a new access token
- The refresh token expires (hopefully not too often, as it requires human intervention) → back to 1.
I somewhat get how it works, but not why it works like this. 3 main questions come to mind:
- Why is the authorization server distinct from the resource server? When I grant an application access to Google Docs, I am prompted to grant authorization on a Google authorization server.
- What is the role of the authorization code? Why can't the authorization server directly return an access token?
- Why can the access token be refreshed by using a refresh token? How is this a security feature? If the expiration of the access token provides some additional security, isn't it defeated by the possibility to get a new one by simply exchanging a refresh token for a new access token? We might as well never expire the access token and do away with the refresh mechanics.
I'll take you down the rabbit hole and explain other safety features of OAuth along the way, just as deep as needed to satisfy my own curiosity, but feel free to dig further!

Authorization and Resource servers
Why are the Authorization and Resource servers distinct? This is mostly for separation of concerns, but brings some security benefits: if an authorization server grants access to resources located on different resource servers, breaking into one resource server doesn't give access to resources on other servers.
The resource server security logic is relatively simple, as it only validates JWT token signatures. The authorization logic being implemented in a single place reduces the attack surface, and teams maintaining authorization servers are often distinct from those maintaining resource servers.
Authorization Code
Why does it exist?
Wouldn't it be easier if the authorization server returned an access token in the redirect URL instead of an authorization code which then must be exchanged for an access token?
It would, and in fact the deprecated OAuth "implicit flow" did just that, but this is less secure, for a few reasons. The most compelling maybe is that the browser history would store the redirect URL containing the access token: malicious browser extensions, or someone gaining access to the user's machine would be able to steal the access token and access the user's resources.
OAuth was also designed to work over HTTP (no S): any machine carrying the traffic between the authorization server and the user's browser could access the token.
Last, any script or image on a page that connects to 3rd party sites includes a Referer header containing the URL of the page that initiated the request. So, a redirect to https://www.myApp.com#access_token=gyt23uy1 would load all the scripts and images on the page, which in turn would include the URL containing the access token in the Referer header. Note: normally, anything after the # sign (hash parameter) in a URL is supposed to never leave the browser, but historical discrepancies in browser implementation proved otherwise, and this was deemed non-standard enough that the behavior should not be trusted. Failure to respect this mandate would also mean that visits to https://www.myApp.com#access_token=gyt23uy1 would be logged by middlewares of our application, which would increase leakage of the token.
There are other possible scenarios, but what I will retain is that the "front channels" (SPA or mobile application) are not as secure as the "back channels" (backend servers), and they should not be trusted to hold sensitive credentials.
Alright, but don't we have the same issue for the authorization code? Isn't it as valuable as the access token? It is not: the access token can be used to access resources on the resource server. The authorization code can be used to obtain an access token, but only in conjunction with the clientId and clientSecret. An attacker with the authorization code could request an access token, but the authorization server would deny it, because it would request the clientSecret paired with the clientId associated to the authorization code in the authorization server's memory, which retains a structure like:
The access token is a right to access a resource. The authorization code is a proof that a given user granted a certain application access to a resource. Here is an analogy:
Let us say I want to hire a business (client application) to check mail in my lockbox at USPS (resource) regularly. First, I would present myself to the teller (authorization server), identify myself and the business I am hiring (with the clientId), and give consent for USPS to hand over the key of the first of my 3 lockboxes (scope definition) to the business. This is recorded in the USPS system, and for the sake of the argument, let us say they also give me a receipt recording that I am willing to grant access to lock box #1 to the business (the authorization code). If I were to lose this receipt and someone other than the business were to find it, they could not redeem it for a key (access token) to the lockbox without being able to prove (because they lack the clientSecret) they are the business I granted access to. So, the receipt is not a sensitive credential. I'd give the receipt to the business, which identifies themselves to the USPS teller, who would verify I only granted authorization to share a key copy for lock box #1 and hand it over. Now, if the business loses the key in the street, we're in trouble, as it is a sensitive credential.
Why so many back-and-forths?
Another question I had was: why bother passing an authorization code to the frontend, which communicates it to the backend, which fetches the access token? Couldn't OAuth have been designed in such a way that authorization requests made for a user of the client application identified by the clientId would conclude with the authorization server sending the access token to a pre-registered webhook on the client application's backend?
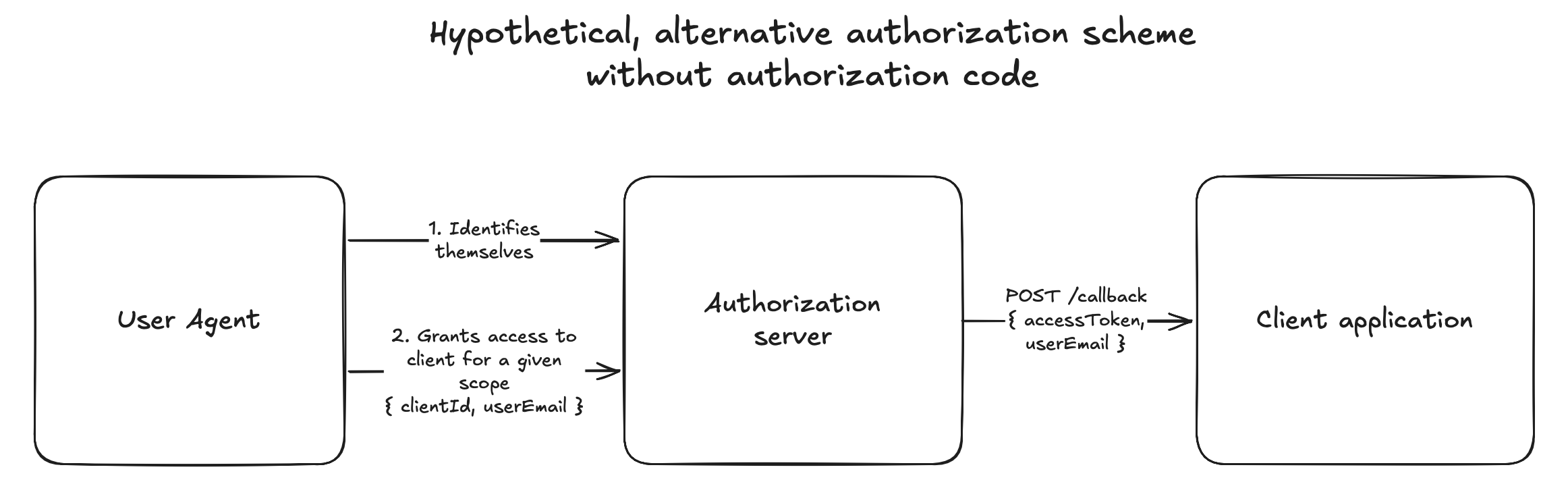
This may pose some security challenges, but does not seem infeasible. The steps would go something like:
- Client application registers itself with the authorization server: it is issued a clientId and clientSecret, and registers a callback hook to receive access tokens
- User identifies itself with the authorization server and grants the client application access to a resource
- The authorization server delivers the access token and user identifier (like an email address) to the client application by hitting its callback URL
I do not think the above architecture would have been impossible. It would have been much simpler to understand. So, why did OAuth go the more complex route? Well, this is because I lost sight of a whole class of applications: Single Page Apps and mobile apps with no backend! These applications do not have a secure server to receive the access token via a push of the authorization server on a callback. They have to request an access token via HTTPS to the authorization server themselves. This answers the question.
!!It is recommended that such apps implement OAuth with a server though.!!
Access and Refresh tokens
The last mystery to elucidate is the safety brought by the Access / Refresh token pairs. I do not understand why the access token expiring would make the system any more secure: if the refresh token is leaked, surely an attacker could mint new access tokens for themselves! Well, no.
There is an essential distinction of nature between the access and refresh tokens:
- The access token is a so-called "bearer" token: this means that anyone in possession of the token gets granted access. It is presented to a resource server, which does not need to burden itself with the knowledge of a clientId (or secret): that is the concern of the authorization server alone.
- The refresh token must be presented with a valid clientId / clientSecret pair to the authorization server. The refresh token alone is useless, it is not a bearer token.
So, client applications should require a new, short lived access token whenever they need access to a resource. Its rapid expiration mitigates the risks of a leak. Refresh token leaks are okay, provided the client secret is not leaked. This is also why SPA / mobile apps cannot make use of a refresh token: they have no secret to protect its use.
There I go, my naive questions are addressed. On top of that, authorization servers can make it so that refresh tokens are single use, and a new refresh token is issued upon each refresh of an access token. This way, if an attacker tries to reuse a refresh token, they will not get an access token. Or, if the client application requests an access token by providing a refresh token already used by an attacker, they will know immediately that their credentials have been compromised.
A detour by PKCE
Proof Key for Code Exchange, or PKCE (pronounced "pixie"), was another bit I didn't know about previously and which puzzled me when I stumbled upon it: how does it increase security in any way?
First, how it works:
- The client application generates a secret random string called the "code verifier". It then uses a hashing algorithm (sha256) to produce a "code challenge":
code_challenge = sha256(code_verifier) - When the user visits the client application login page, the client application redirects the user to the authorization server, and passes the code challenge as part of the payload, along with the clientId, scope and redirect uri
- The authorization server saves the code challenge for later and associates it to the authorization code it issues
- The authorization code is presented by the client application to the authorization server, along with the code verifier
- The authorization server recomputes the code challenge from the code verifier, and verifies that it matches the code challenge saved earlier. If so, it knows that the party that comes to claim the access token is the same party that initiated the initial request
PKCE ensures that the entity redeeming the access token against the authorization code is the same as the entity that requested the authorization code.
For applications with a secure backend channel, the added value of PKCE is not clear to me, it seems redundant: only the application with a clientId / clientSecret pair associated with the authorization code can redeem the access token.
PKCE's value shines for SPA / mobile applications though. It is better understood by looking at an attack scenario without PKCE:
- Mobile applications typically cannot listen on localhost, so they have to register a custom URI scheme with the authorization server, something like:
myapp://authorization_code_callback - Nothing prevents a malicious application from claiming the same URI scheme
- The mobile OS, when it processes the redirect to the custom URI scheme, has to choose which application to deliver the authorization code payload to. Some OS may ask the user to choose, others may pick one arbitrarily
- If the malicious application gets the authorization code, it can redeem it for an access token, since there is no client secret to present to the authorization server
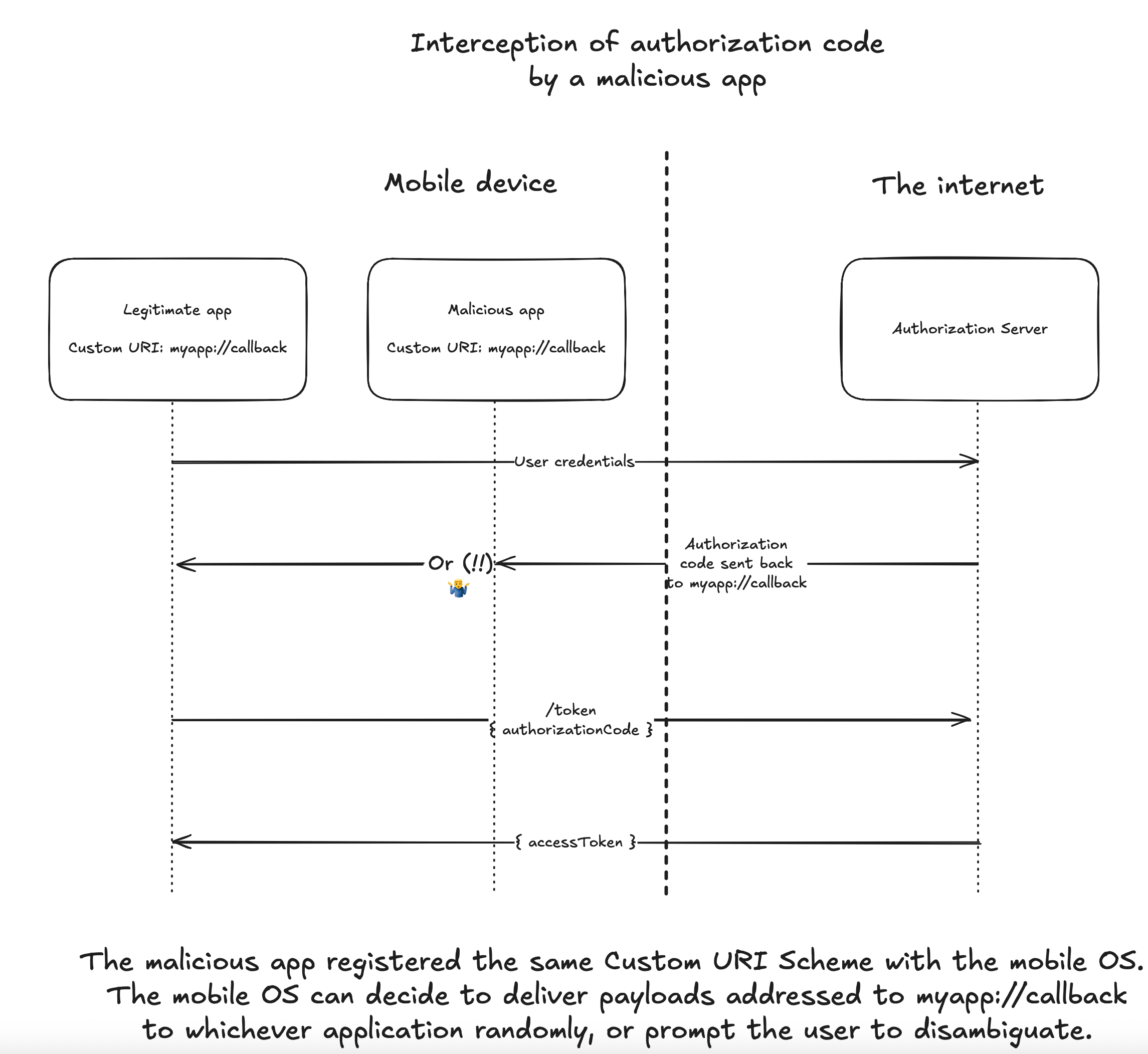
With PKCE, the legitimate application generates the code verifier internally, passes the code challenge to the authorization server when requesting the authorization code, and then during a safe HTTPS call to request the access token it includes the code verifier. If the malicious application has intercepted the authorization code, it cannot redeem it for an access token because it will fail to submit the proper code verifier.
Moving on
Alright, this is enough digging for me at the moment. I do not pretend to understand all the intricacies of OAuth, the usage of the state parameter as a CSRF token during the authorization code request still escapes me for example, but at least the design of OAuth makes more sense to me. I'll add to this knowledge as I go.