Context is king: tools for feeding your code and website to LLMs
LLMs excel at automating code and content tasks, but their accuracy depends on the context you provide—especially as your codebase evolves. Learn key tools and techniques to keep your AI assistants up to date.
Large Language Models (LLMs) automate tasks from code generation to website content updates. But no matter how powerful these models seem, they’re only as good as the information you feed them - especially if your source code or content changes frequently.
Why context matters
LLMs like GPT or Claude excel at generating text, but without direct access to your codebase or documentation, they often rely on guesswork.
Supplying them with a reliable “digest” of your code, API references, and domain-specific docs ensures they can provide relevant and correct answers.
Gitingest: Turn any GitHub repo into a prompt-friendly text file
One popular tool mentioned recently is Gitingest. The premise is simple:
You give Gitingest the URL to any public GitHub repo, which it then reads and converts into a single text file (minus binaries).
You can also replace hub with ingest In any public GitHub repo URL to get the generated llm.txt directly.
For instance, if your repo is at https://github.com/workos/authkit-nextjs, you can open https://gitingest.com/workos/authkit-nextjs to view the generated llm.txt.
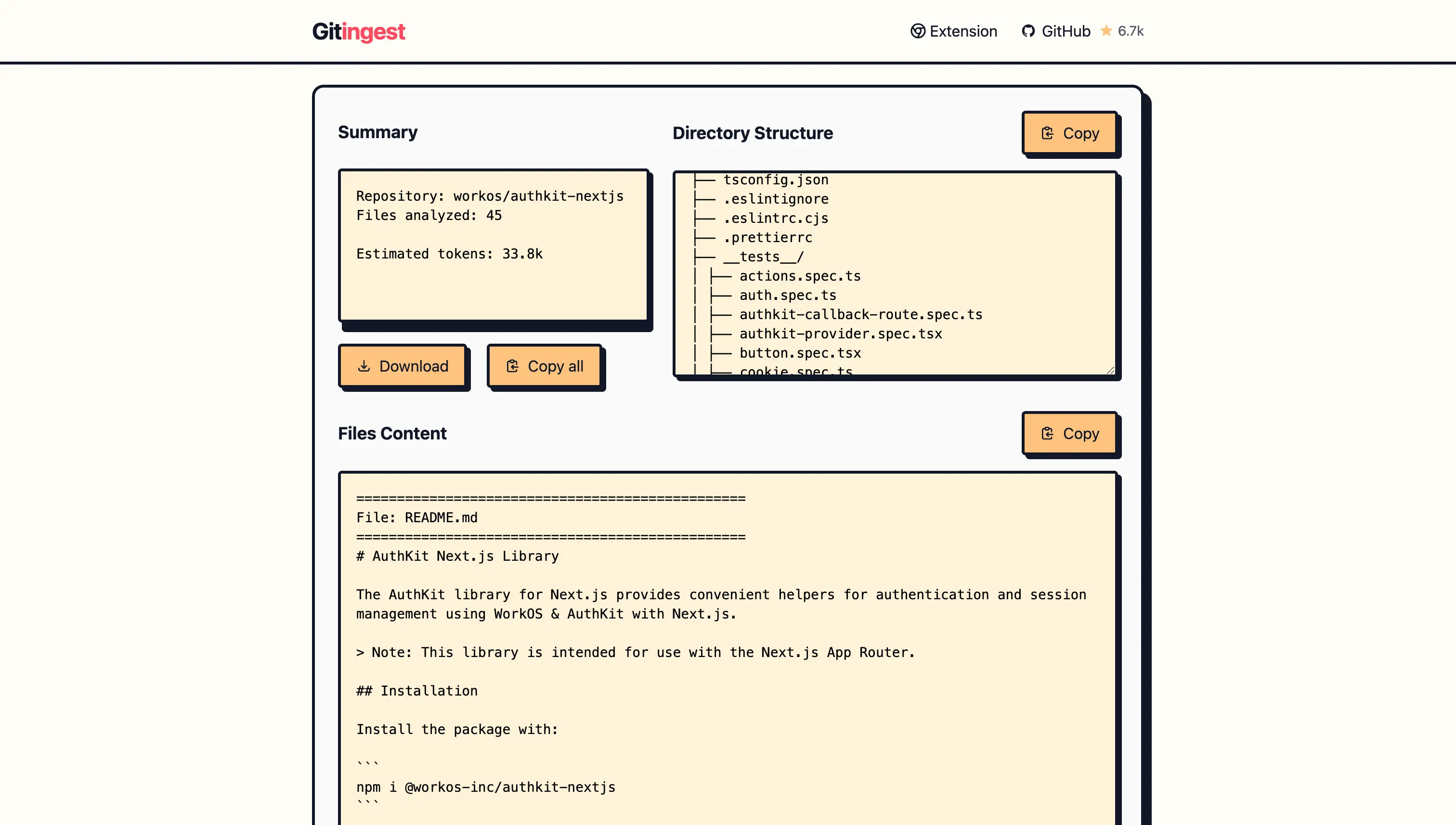
By copying that text into your favorite LLM chat window or plugging it into a prompt, you can give AI a better understanding of your codebase.
This text is LLM-friendly, so it’s easier to reference the entire repository in one shot.
Local repository digests via a custom script
If you’d rather keep everything offline, you can roll your own script to produce a text dump locally. For instance, Nick Nisi shared an example repo-digest.sh script to:
- Clone or navigate to your repo.
- Walk through each file (excluding binaries).
- Append or format each file’s contents into a single .txt file or just stdout.
Note that you may need to adjust the script to exclude files you're not interested in, but here’s a minimal example for reference:
#!/usr/bin/env bash
REPO_PATH=${1:-.}
OUTPUT_FILE="repo-digest.txt"
echo "Generating digest for $REPO_PATH..."
> "$OUTPUT_FILE"
find "$REPO_PATH" \
-type f \
! -path "*/.git/*" \
! -path "*/node_modules/*" \
-exec file --mime-type {} \; \
| grep "text/" \
| cut -d: -f1 \
| while read -r file; do
echo "==== FILE: $file ====" >> "$OUTPUT_FILE"
cat "$file" >> "$OUTPUT_FILE"
echo -e "\n" >> "$OUTPUT_FILE"
done
echo "Digest written to $OUTPUT_FILE"
Run ./repo-digest.sh /path/to/your/repo and you’ll get a repo-digest.txt that you can feed directly into a prompt for local AI tools like Claude or GPT.
Using Cursor’s native @docs Integration
Cursor features a native @docs command that lets you reference external documentation seamlessly. Pointing Cursor to third-party URLs can dynamically fetch the latest docs and store them for contextual lookups throughout your coding session—no manual copy-pasting required.

How It Works
- Add @docs lines in your prompt: Prefix external doc URLs with @docs, and Cursor will automatically ingest the content.
- Ask context-aware questions: Once the documents are indexed, you can ask questions using natural language. Cursor will pull relevant sections from the ingested documentation.
- Stay up to date: Because Cursor fetches documentation at ingestion time, it’s easy to re-run @docs commands when docs update, ensuring you always have the latest information.
Why this is useful
- Centralized knowledge: Rather than juggling browser tabs or local text dumps, the @docs command keeps your reference material right in your IDE session.
- Less context switching: Seamlessly integrate documentation queries into your coding workflow without leaving your editor.
- Reduced hallucination: Providing direct doc references lowers the chance of the AI “inventing” APIs or methods that don’t actually exist.
By leveraging Cursor’s @docs integration in tandem with other digesting or context-feeding tools (like Gitingest or local scripts), you’ll have a powerful ecosystem where LLMs can accurately reference your code and the latest docs—paving the way for faster, more reliable development.
The spec file pattern
It’s very powerful to start a new project by writing a highly detailed technical spec that describes the project, its goals, its exact tech stack, desired patterns and coding styles, etc. You can then continuously refer to this file using Cursor’s file reference utility in Composer or chat windows: @spec.md.
llms.txt for websites
Another emerging idea is to have a dedicated llms.txt file, similar to robots.txt, that houses key site content (or instructions) for LLM indexers. While not yet an official standard, it’s part of a growing conversation about how to explicitly serve up relevant website context to AI.
This proposal outlines a simple, Markdown-based file called /llms.txt that websites can host at their root to help large language models (LLMs) quickly find and use relevant information.
It works like a specialized “cheat sheet” for LLMs—similar in spirit to robots.txt or sitemap.xml, but aimed at making curated, plain-text documents available to language models at inference time.
Core ideas:
- A single, easily parsed file, llms.txt, provides an overview (e.g., project details, key points) plus links to deeper Markdown resources.
- Clean Markdown versions: Each page in a site can offer an “.md” variant (e.g., /about.html.md), so LLMs can skip the clutter of HTML/JS and get straight text.
- Lightweight, flexible spec: The file starts with an H1 (project name), a blockquote summary, then optional sections and links. A special “Optional” section identifies links that can be safely omitted to fit context size limits.
- Complements existing standards: /llms.txt doesn’t replace sitemaps or robots.txt. Instead, it surfaces key content so LLMs aren’t forced to parse entire websites or guess important pages.
Benefits:
- Helps code-focused models quickly grab relevant docs and APIs.
- Provides curated, expert-friendly content for businesses, personal sites, or technical documentation.
- Standardizes the location and format of LLM-related docs, making it easier for tools and agents to fetch what they need on demand.
The proposal is currently open for community input; real-world usage examples (e.g., the FastHTML docs) demonstrate how /llms.txt can unify and streamline knowledge for large language models.
Replit Ghostwriter
Replit Ghostwriter is another AI-powered coding assistant that analyzes your workspace in real-time. When you open a project in Replit:
- Real-time code indexing: It scans your existing code to maintain a context map.
- Autocompletion + docs: You can highlight a function call or snippet, and Ghostwriter will explain it or provide relevant documents—sometimes fetching references from well-known document sites.
- Error correction: When errors pop up, Ghostwriter can leverage the project’s context to suggest fixes, referencing known syntax or library constraints.
Context today and tomorrow
Integrating LLMs into your dev workflow is much smoother when they have full visibility into your code and docs. Tools like Gitingest, local digest scripts, and even new ideas like llms.txt can help you build or share prompt-friendly data.
If you’re looking for further inspiration, Supabase has AI Prompts docs that give curated examples of how to interact with their platform via ChatGPT or similar tools. Consider creating your own “AI Prompts” guide for your team or users, so they can quickly tap into the power of your codebase with AI.
The trend behind all these solutions is clear: LLMs grow more reliable with direct access to real data rather than relying on their built-in training alone. Developers everywhere are:
- Reducing hallucinations: By handing the model your actual docs, code, or knowledge base, you minimize the model’s inclination to “make stuff up.”
- Accelerating workflows: AI can handle more advanced tasks (like complex refactors or multi-step tutorials) when it understands your environment.
- Standardizing best practices: Company-wide style guides or code standards can be ingested once, letting AI automatically enforce them in suggestions.
All of this supports the idea that context is king: the more relevant data you can feed your LLM, the more precise and valuable its contributions will be.