Generative AI at the edge with Cloudflare Workers
Large language models are reshaping how we build apps—but is your infrastructure ready for them?
As developers adopt LLMs, vector databases, and inference pipelines, they’re encountering hidden roadblocks: infrastructure that doesn’t scale smoothly, inconsistent global performance, and overwhelming complexity managing compute resources.

Cloudflare Workers offers an intriguing solution - allowing you to deploy globally-distributed, serverless infrastructure that's fast enough to support next-generation AI workloads.
In this post, we'll configure, deploy and test a Cloudflare Worker at the edge. and we'll consider how edge computing platforms like Cloudflare Workers address common challenges for AI workloads.
The technical challenges of scaling AI applications
AI workflows present distinct infrastructure requirements compared to traditional web applications:
Variable and unpredictable workloads
AI services often experience extreme traffic fluctuations. During peak times, you might need to handle thousands of inference requests per second, while other periods might see minimal activity.
Global latency requirements
For real-time AI applications, network round-trip times can significantly impact user experience. Achieving consistent response times under 100-200ms requires strategic global deployment.
Resource coordination complexity
Traditional GPU-accelerated deployments involve:
- Orchestrating container clusters for model serving
- Managing GPU resource allocation and sharing
- Implementing queuing, batching, and concurrency controls
These challenges often lead to over-provisioning, which results in idle GPU capacity and unnecessary costs, or under-provisioning, which causes performance degradation during traffic spikes.
Edge computing for AI workloads
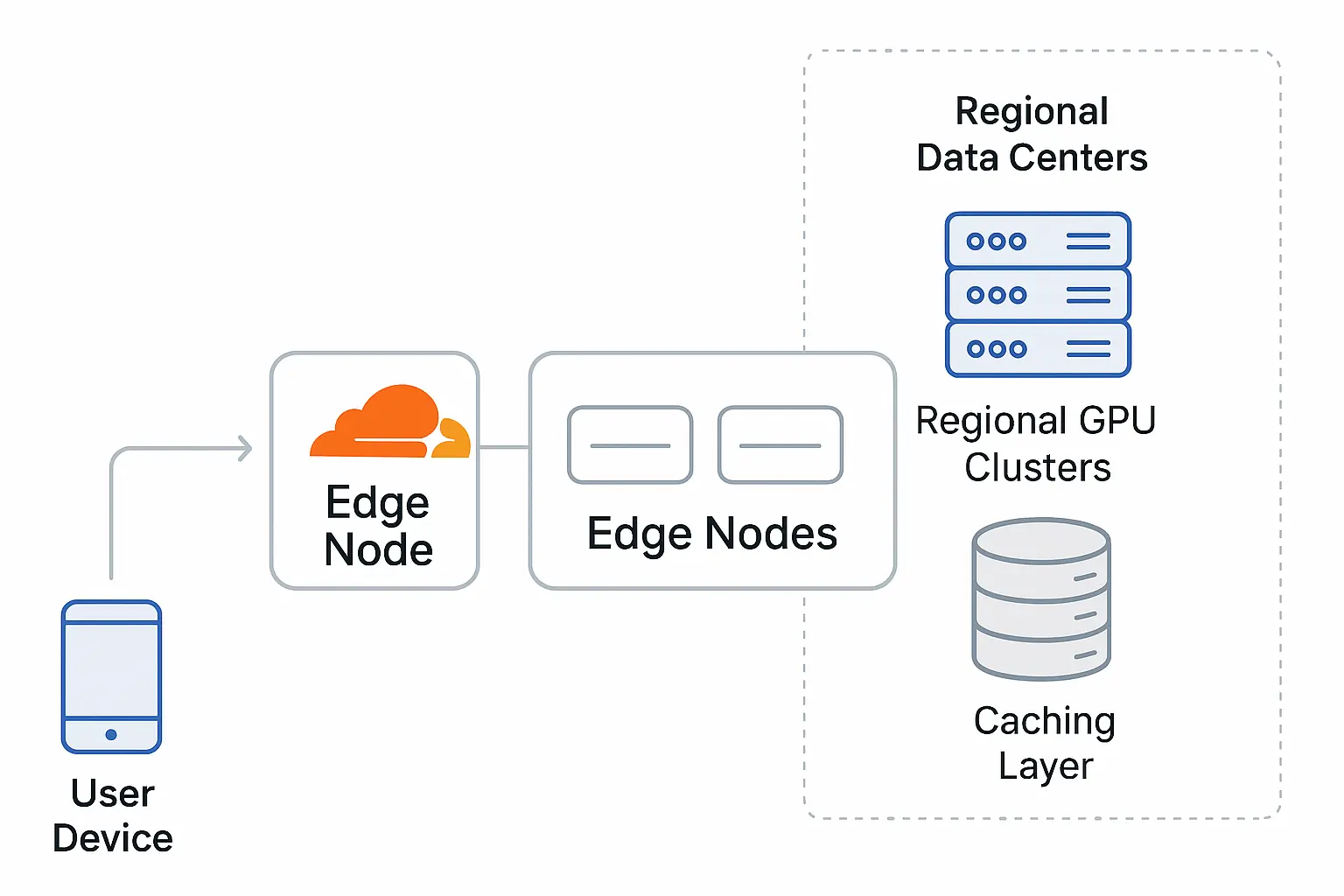
Edge computing platforms, like Cloudflare Workers, distribute computation across a global network of data centers. This architecture provides several advantages for AI applications:
Reduced latency through geographic distribution
Edge platforms execute code in data centers close to end users, significantly reducing round-trip times. For applications like real-time content moderation or personalization, this can cut response times by hundreds of milliseconds compared to centralized deployments.
Serverless GPU access
Platforms like Cloudflare Workers AI provide programmatic access to GPU-accelerated models without requiring you to provision or maintain GPU hardware. This abstracts away the complexity of GPU cluster management through a consumption-based model.
Integration with memory and storage services
Edge platforms typically offer complementary services that address AI-specific needs:
- Vector databases for embedding storage and similarity search
- Key-value stores for caching and session state
- Durable storage for model weights and configuration
Fine-grained resource scaling
Serverless platforms can automatically scale compute resources based on actual usage, often at a more granular level than traditional Kubernetes-based deployments. This provides better resource utilization, particularly for bursty AI workloads.
Implementing AI at the edge with Cloudflare Workers
Now that we've explored the conceptual benefits of edge computing for AI workloads, let's examine how to implement these solutions using Cloudflare Workers.
Getting Started with Wrangler and Workers AI
To begin developing with Cloudflare Workers AI, you'll need to set up the Wrangler CLI tool, which is the primary development interface for creating and deploying Workers projects.
Install Wrangler
npm install -g wrangler
Authenticate Wrangler
wrangler login
Create a new Workers project
wrangler init ai-text-generator
cd ai-text-generatorThe Wrangler CLI will set up your project locally, install all necessary dependencies and configure a wrangler.toml for you automatically:
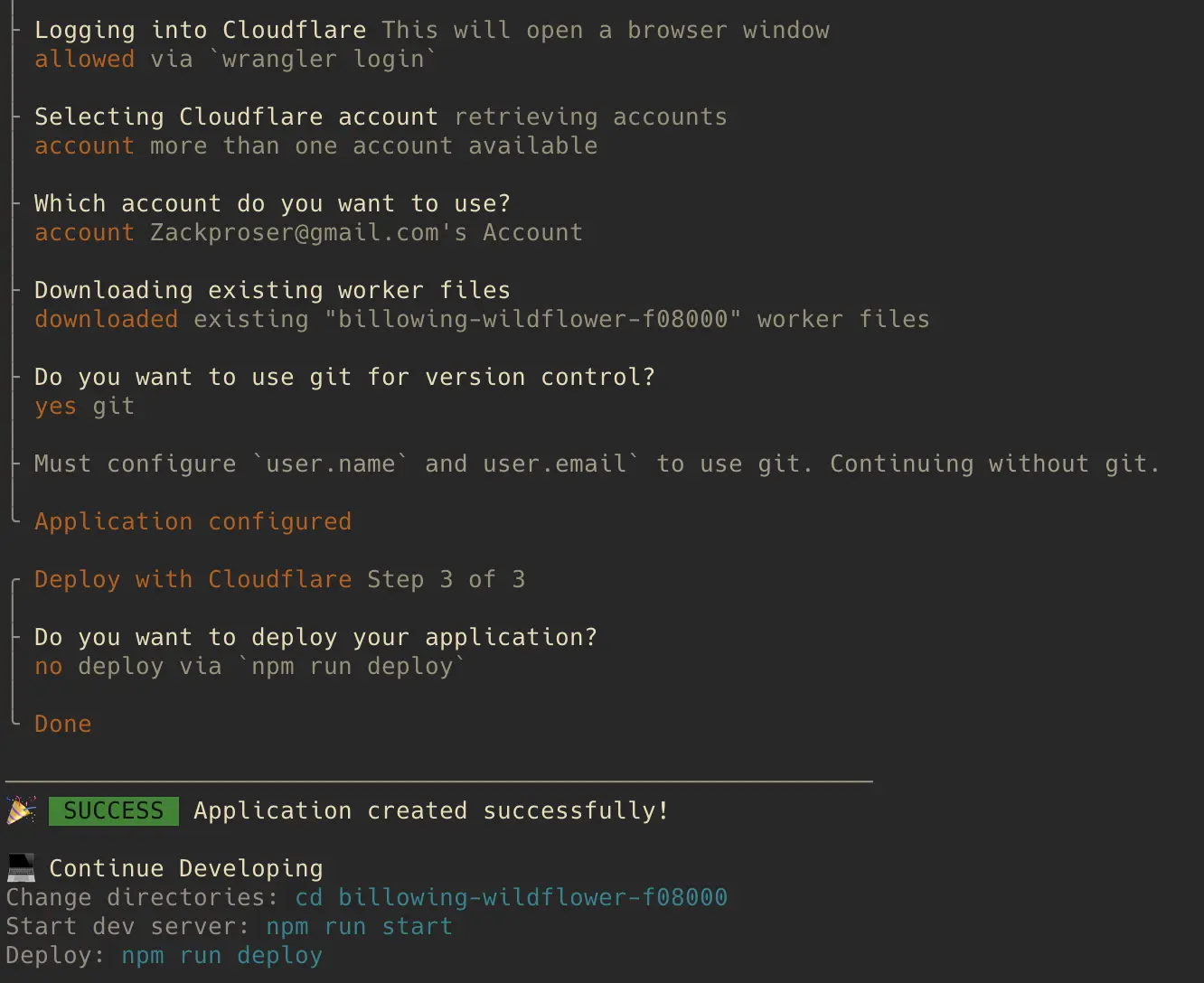
From this point, you can develop and test your worker locally with npm run dev or deploy your changes live with npm run deploy .
Configure your project for AI capabilities
Add the following to your wrangler.toml file to enable AI capabilities through environment bindings:
name = "ai-text-generator"
compatibility_date = "2024-04-01"
main = "src/worker.js"
workers_dev = true
preview_urls = false
[ai]
binding = "AI"Create your edge-based text-generating worker
Create the src/worker.js file that will run when our Cloudflare worker handles a request at the edge. This worker uses the quantized Llama-2-7B chat model to respond to the end user's prompt:
export default {
async fetch(request, env) {
// Parse request body
let body;
try {
body = await request.json();
} catch (e) {
return new Response("Invalid JSON", { status: 400 });
}
// Validate input
const userPrompt = body.prompt;
if (!userPrompt) {
return new Response("Missing 'prompt' field", { status: 400 });
}
try {
// Call @cloudflare/ai text generation model
const response = await env.AI.run('@cf/meta/llama-2-7b-chat-int8', {
messages: [
{ role: 'system', content: 'You are a helpful assistant.' },
{ role: 'user', content: userPrompt }
],
max_tokens: 256,
temperature: 0.7
});
// Return the generated text
return new Response(JSON.stringify({
generated_text: response.response
}), {
headers: { 'Content-Type': 'application/json' }
});
} catch (error) {
console.error("AI inference error:", error);
return new Response(`AI processing error: ${error.message}`, {
status: 500
});
}
}
};This example demonstrates several key concepts:
- The Worker accesses the AI model through an environment binding, avoiding the need to manage API keys in your code.
- The implementation includes proper error handling for both request parsing and model inference.
- The code specifies relevant parameters like temperature and token limits, giving precise control over generation characteristics.
- The entire implementation requires minimal boilerplate compared to traditional server-based approaches.
To deploy your changes, run npm run deploy:
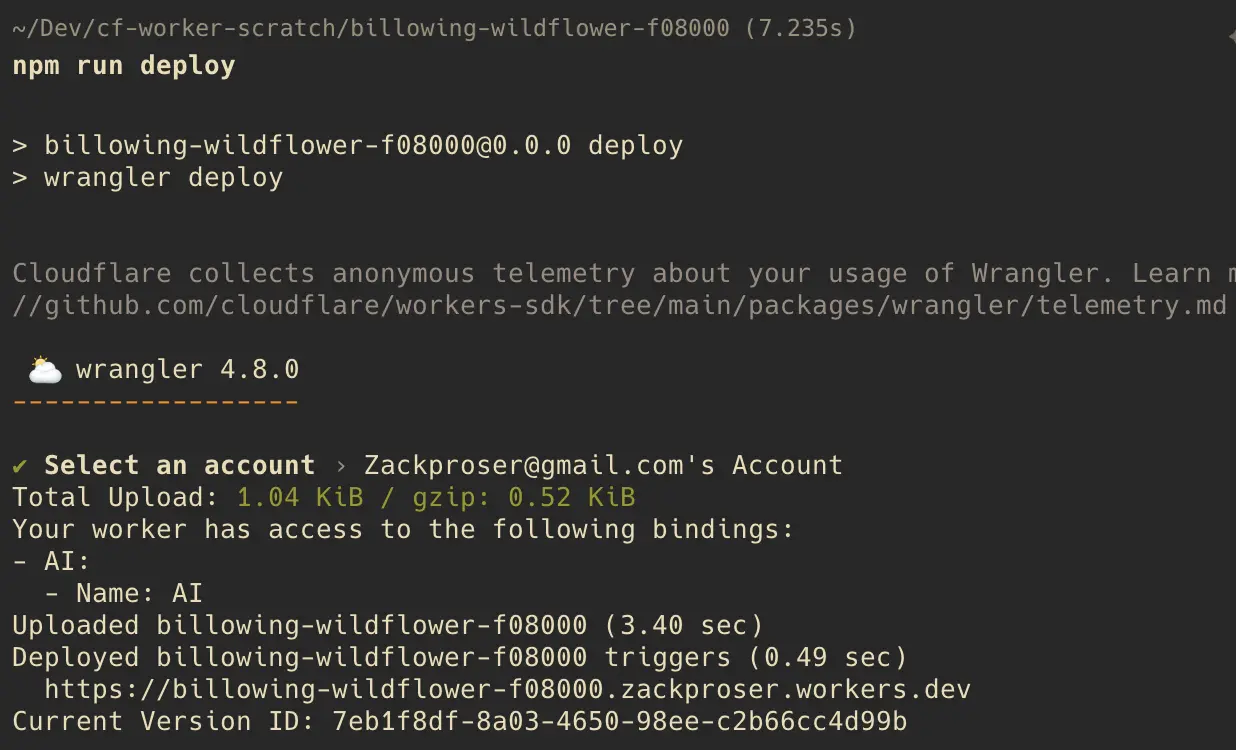
Verifying and testing your workers deployment
Ensure that your deployment has access to the AI bindings as shown in the above screenshot. If not, check your wrangler.toml again and ensure it matches the above example.
When the deployment is complete, you can issue a curl request to test out your AI worker:
curl -X POST https://billowing-wildflower-f08000.zackproser.workers.dev/ \
-H "Content-Type: application/json" \
-d '{"prompt": "Explain the edge to me using only emojis?"}'
# If all goes well, you should get a response from your LLM-backed worker!
{"generated_text":"🏔️🔥💥👀"}% Edge AI architecture considerations
When designing AI applications for the edge, several architectural patterns emerge:
Hybrid model execution
Not all AI workloads are suitable for edge execution. The most effective architectures often use:
- Edge locations for lightweight models (embeddings, classification, small LLMs)
- Regional GPU clusters for compute-intensive models (large diffusion models, 70B+ parameter LLMs)
- Intelligent routing between these tiers based on request characteristics
Effective caching strategies
AI outputs often have high reuse potential. Implementing multi-level caching can dramatically improve performance:
- Request-level deduplication for identical inputs
- Result caching with appropriate TTLs
- Semantic caching based on embedding similarity
Chain-of-thought processing
Complex AI workflows often involve multiple steps (e.g., classification → generation → summarization). Edge platforms excel at orchestrating these workflows by:
- Processing initial steps at the edge
- Routing to specialized compute resources when needed
- Assembling final results before responding to clients
Technical limitations and considerations
While edge computing offers significant advantages for AI workloads, it's important to understand its constraints:
Memory limitations
Edge computing environments typically have stricter memory constraints than dedicated servers. This impacts:
- The size of models that can be loaded (often limited to <10GB)
- The context window length for LLMs (the amount of text a model can process at once, including both input prompt and generated output)
- Batch processing capabilities
Cold start latency
Serverless platforms may experience "cold starts" when loading models into memory. Strategies to mitigate this include:
- Keeping frequently used models "warm" through periodic requests
- Implementing fallback paths during initialization
- Using distilled models optimized for edge deployment
Model availability and selection
Cloudflare Workers' AI integration provides access to specific pre-trained models rather than allowing you to deploy arbitrary models. The available models include:
- Text generation models (e.g., Llama 2, Mistral)
- Embedding models
- Image classification and generation models
- Text-to-image models
When designing your application, you'll need to select from these available options rather than uploading custom models.
Regional availability
Not all edge providers offer GPU acceleration in every region. Applications requiring global low-latency may need to:
- Design graceful degradation paths when GPUs aren't regionally available
- Implement smart routing to balance between latency and model capability
- Consider multi-provider strategies for truly global coverage
Conclusion: The future of edge AI
As models become more efficient and edge computing capabilities expand, we're likely to see increasingly sophisticated AI workloads moving to the edge. For developers, this means the opportunity to build AI applications with:
- Improved global performance characteristics
- Simplified operational overhead
- More efficient resource utilization
- Greater cost predictability
By thoughtfully partitioning workloads between edge locations and specialized compute resources, you can create architectures that deliver both performance and flexibility.