How to secure RAG applications with Fine-Grained Authorization: tutorial with code
With RAG and GenAI applications, how can you ensure users only see results from documents they have permission to access? In this runnable tutorial, we demo using WorkOS Fine-Grained Authorization to secure your documents.
Your Retrieval Augmented Generation (RAG) applications are built on documents from many different departments, customers, or organizations.
How do you ensure users only search through documents they're authorized to see?
In this tutorial, we demonstrate how to implement secure document access control in a RAG application using WorkOS FGA (Fine-Grained Authorization) integrated with Pinecone's vector database.
The companion repository is available here, if you'd like to skip ahead and run the demo yourself.
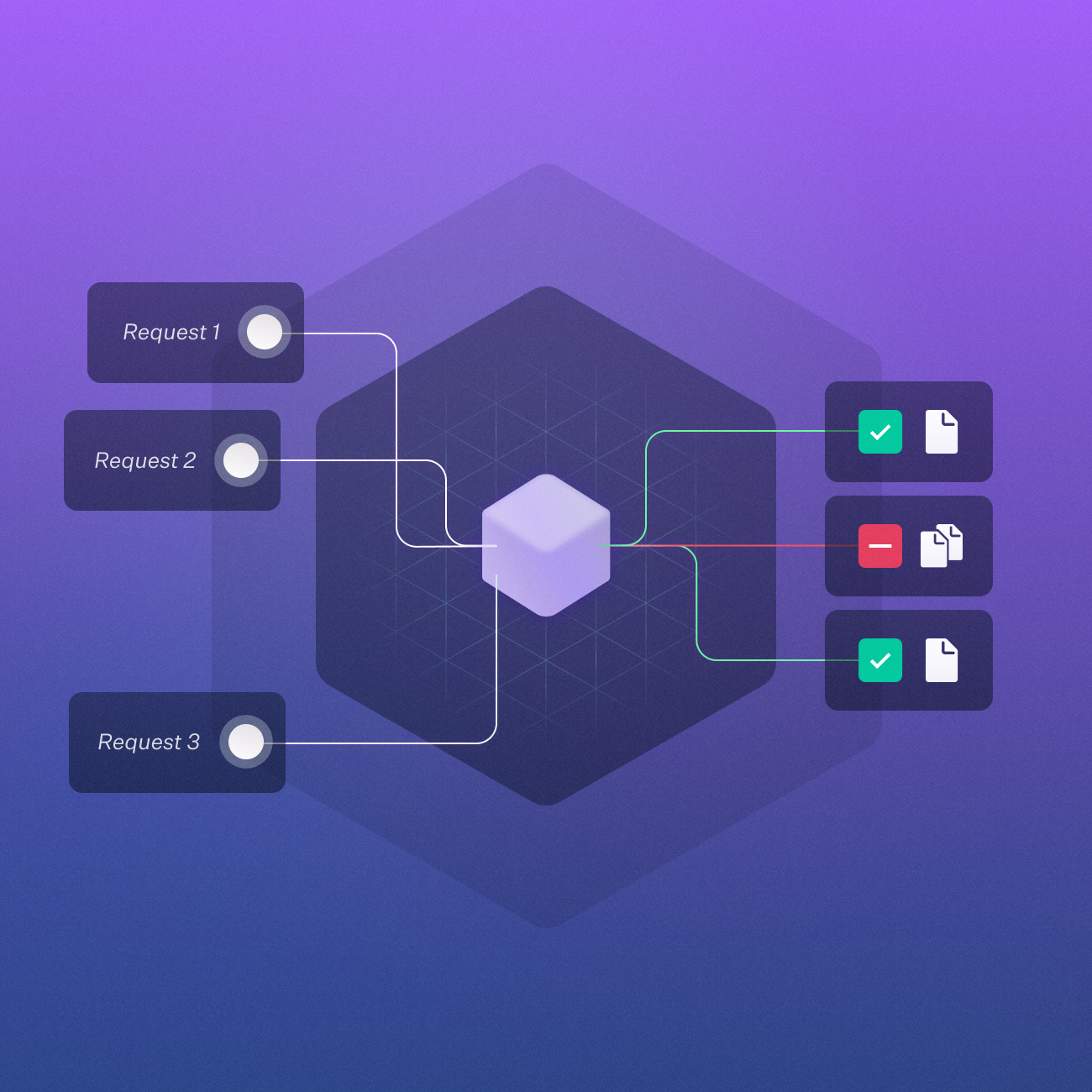
Enter WorkOS Fine-Grained Authorization (FGA)
WorkOS FGA is a flexible authorization system that allows you to define granular permissions on a per-resource basis.
In this tutorial, we'll use FGA to define document ownership, viewing permissions, and document sharing.
We'll implement a runtime access control layer on top of the Pinecone vector database to filter search results based on user permissions.
How it works
Let's break down how our proof-of-concept works:
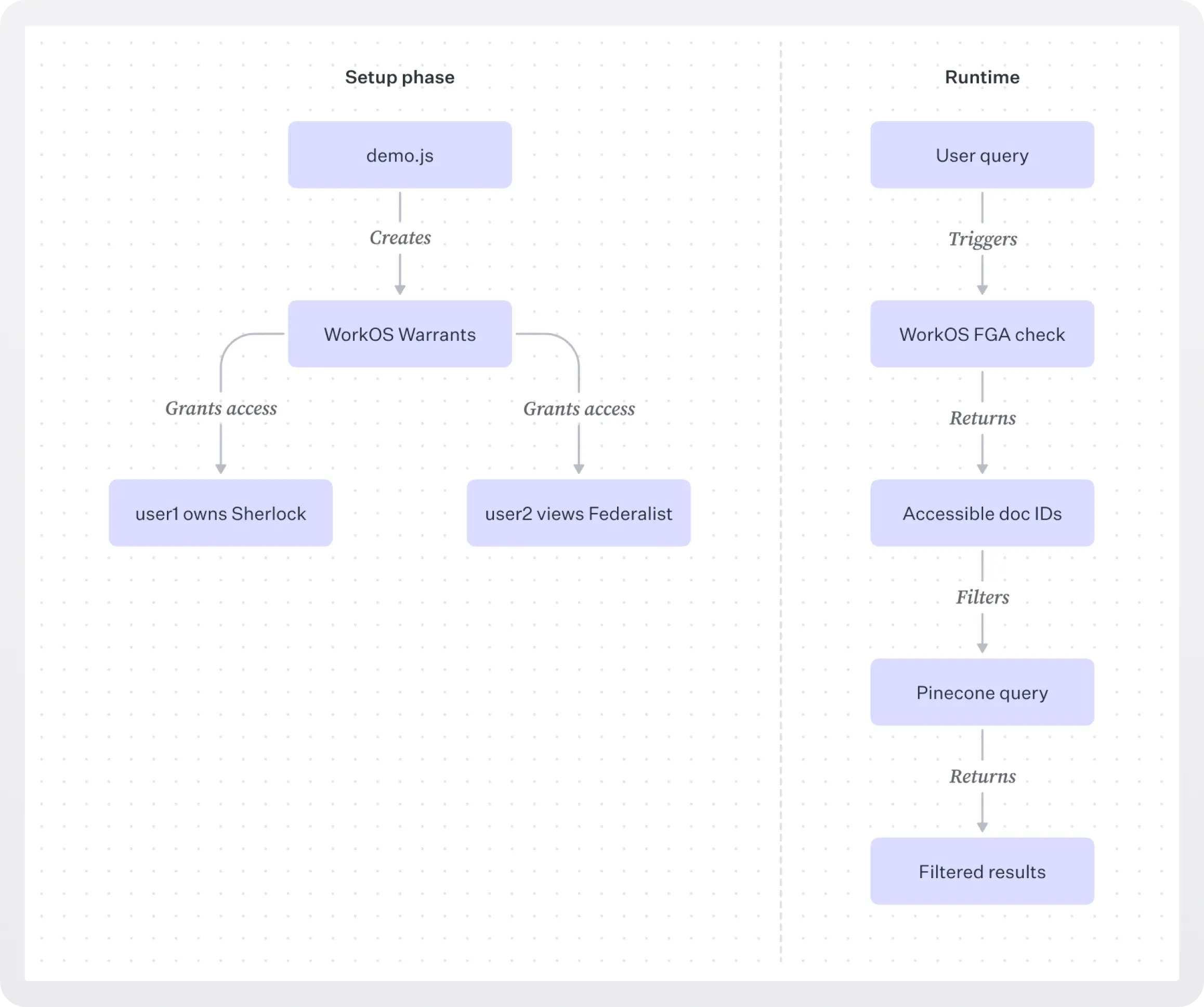
First, we define our authorization model using WorkOS FGA. The model consists of two resource types, document and user.
FGA is designed to be flexible: your resources can be anything you want, and you can define relations between resource types.
Visit the FGA Workos dashboard and enter the following code into the Schema section.
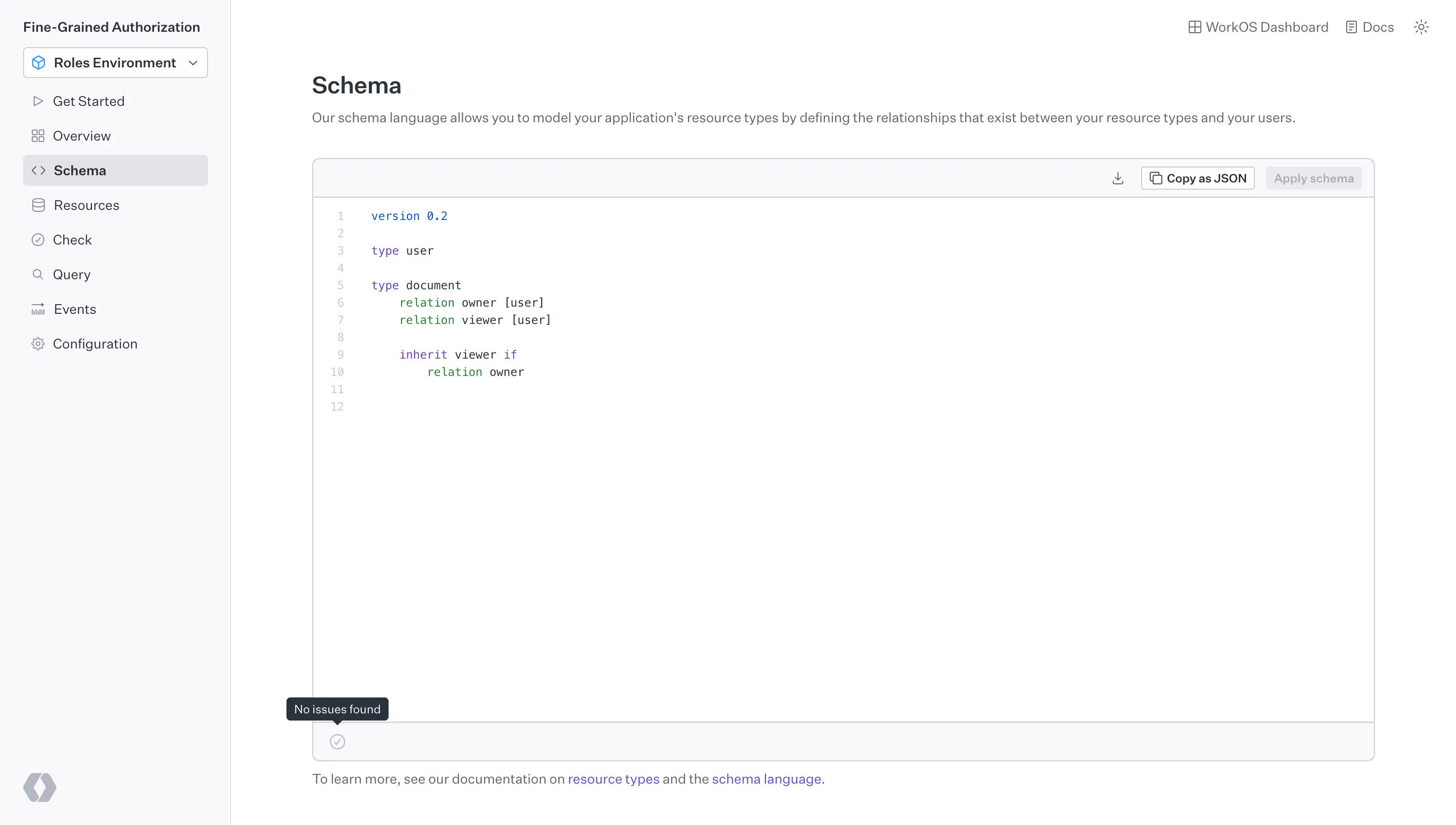
In this case, we're defining an owner relation between documents and users, and a viewer relation that inherits from owner :
This creates:
- A user resource type to represent system users
- A document resource type with owner and viewer relations
- Permission inheritance: document owners automatically get viewer access
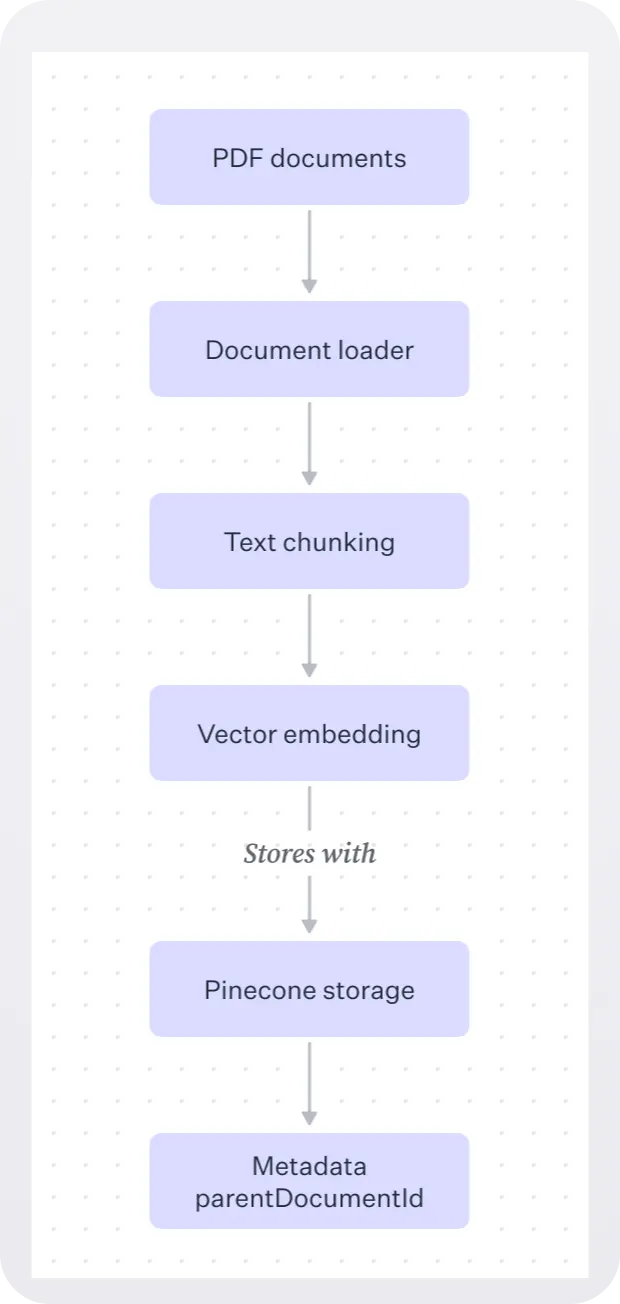
Step 2. Processing documents for vector search
To provide a more realistic end-to-end example, we'll ingest, chunk, and convert a set of PDF documents into vector embeddings and then upsert them to Pinecone. Here's what that process looks like:
We've supplied a few sample documents in the companion repository that live in the data directory:
In the setupPinecone.js script, we use a PDFLoader to load a given PDF into memory and split it into chunks:
We loop through each document, chunk it, and convert it to embeddings, which are arrays of floating point numbers output by a neural network that represent features of the data.
We then upsert the embeddings representing that chunk to Pinecone, attaching the parent document ID as metadata so we can filter by it later:
In our case the stable document ID is a simple modification of the document path, e.g:
doc_sherlock-holmesdoc_federalist-papers
In a production system, you might want to use a more complex ID scheme, e.g. a hash of the document contents.
If we log into the Pinecone dashboard now, we'll see something like the following:
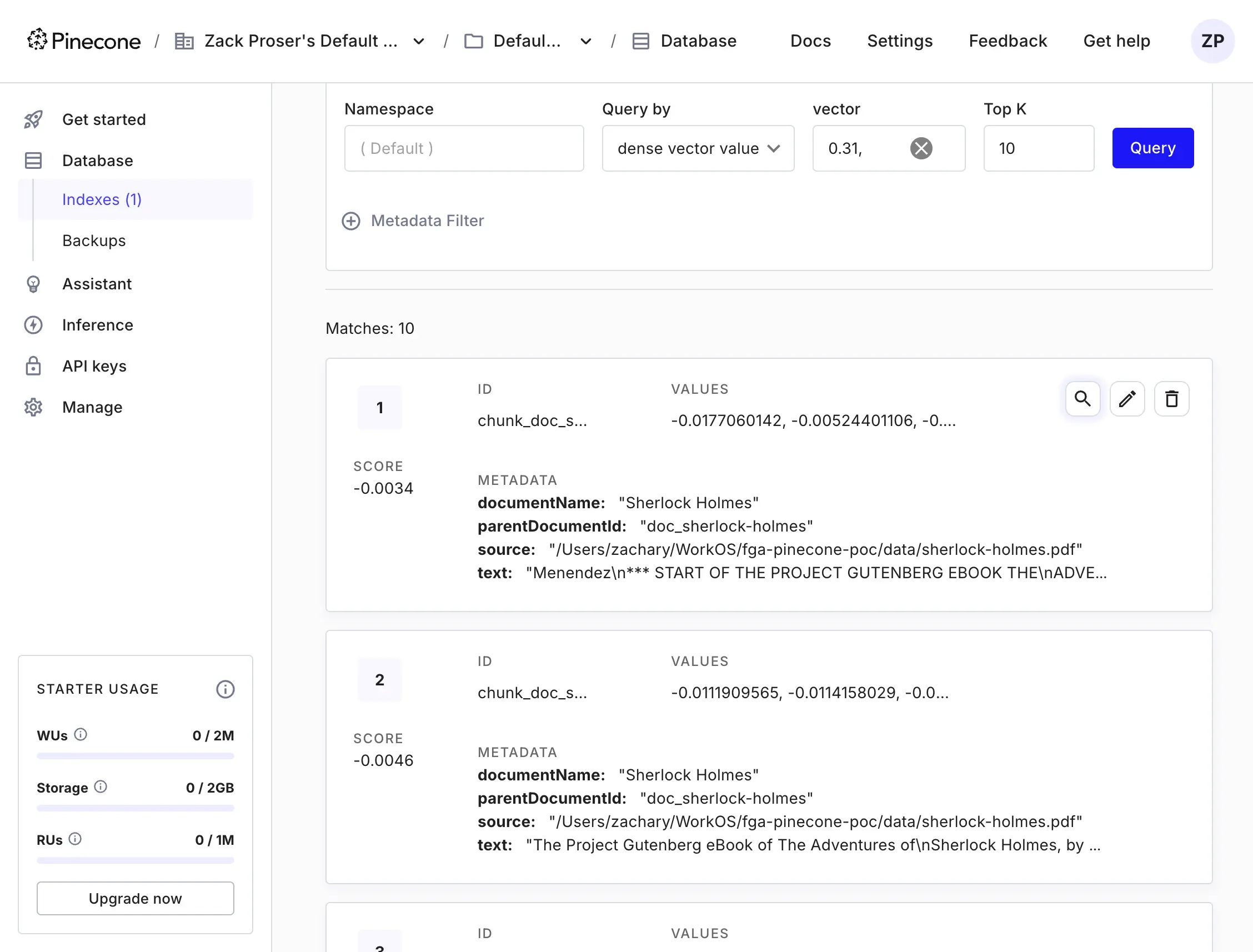
Note that each chunk has a parentDocumentId metadata field that corresponds to the ID of the document it originated from.
Step 3. Runtime access control
In the demo.js script, we'll create a few sample warrants to demonstrate how FGA works.
Warrants are access rules that specify relationships between entities in your application.
We'll give user1 owner access to "Sherlock Holmes" and user2 viewer access to "The Federalist Papers":
This shows how you can create user permissions at runtime using WorkOS FGA's warrant APIs.
Also at runtime, we determine the list of documents a user has access to by using FGA's powerful query API:
This solution uses FGA's query language to find all documents where the user has viewer access. Remember that our schema defines owners as implicit viewers, so this single query catches both cases.
The function returns a list of document IDs the user can access, or an empty array if the user has no access.
Now that we know which documents a user has access to, we can filter our vector search results accordingly.
Metadata filtering is a feature supported by many vector databases allowing you to specify simple or advanced operators on metadata fields when querying for results:
In the above query, we’re telling Pinecone that we want chunks that semantically match the user’s query.
We’re also passing the metadata filter stating that the chunks must also have a parentDocumentId value in the array of accessibleDocs to be included in the result set.
This ensures:
- We efficiently check user permissions with a single FGA query
- Only documents the user can access are included in the search results
- Results are filtered using Pinecone metadata filters
Let's look at the scenario from the demo output:
Note, you can view the expected demo output here in the companion repository README if you don't want to run the code yourself.
- User1 is granted owner access to "Sherlock Holmes"
- User2 is granted viewer access to "The Federalist Papers"
- User3 has no access to any documents
When searching for "What are the principles of justice and liberty?":
- User1 only sees results from Sherlock Holmes
- User2 only sees results from The Federalist Papers
- User3 sees no results
This demonstrates how FGA effectively controls access at the document level while maintaining good performance through its query API and Pinecone's metadata filtering.
Step 4. Implement document sharing with FGA
One of the powerful features of FGA is the ability to manage permissions dynamically. Let's look at how we implement document sharing in our demo:
To make things more realistic, our sharing code implements an ownership check. We verify that the user attempting to share owns the document.
In our demo output, we see this in action:
After sharing, user4 can now search across both documents. This demonstrates how FGA makes it easy to implement dynamic permission changes while maintaining security boundaries.
This approach is transparent to the search functionality - our searchPineconeWithAccess function automatically picks up the new permissions through the getAccessibleDocuments check, requiring no changes to the search logic.
Get started with WorkOS FGA
This tutorial demonstrated how to use WorkOS FGA to control access to RAG applications.
With WorkOS FGA, you get fast, large-scale authorization checks and a system flexible enough to handle even the most complex use cases.
You can define your authorization model once and enforce it across micro-services, applications, cloud environments, and more. You can define and manage your resources, hierarchies, access policies, and inheritance rules from the FGA dashboard or programmatically with the FGA API or the WorkOS CLI.
To start with WorkOS FGA, sign up for a free WorkOS account and follow the quickstart guide.