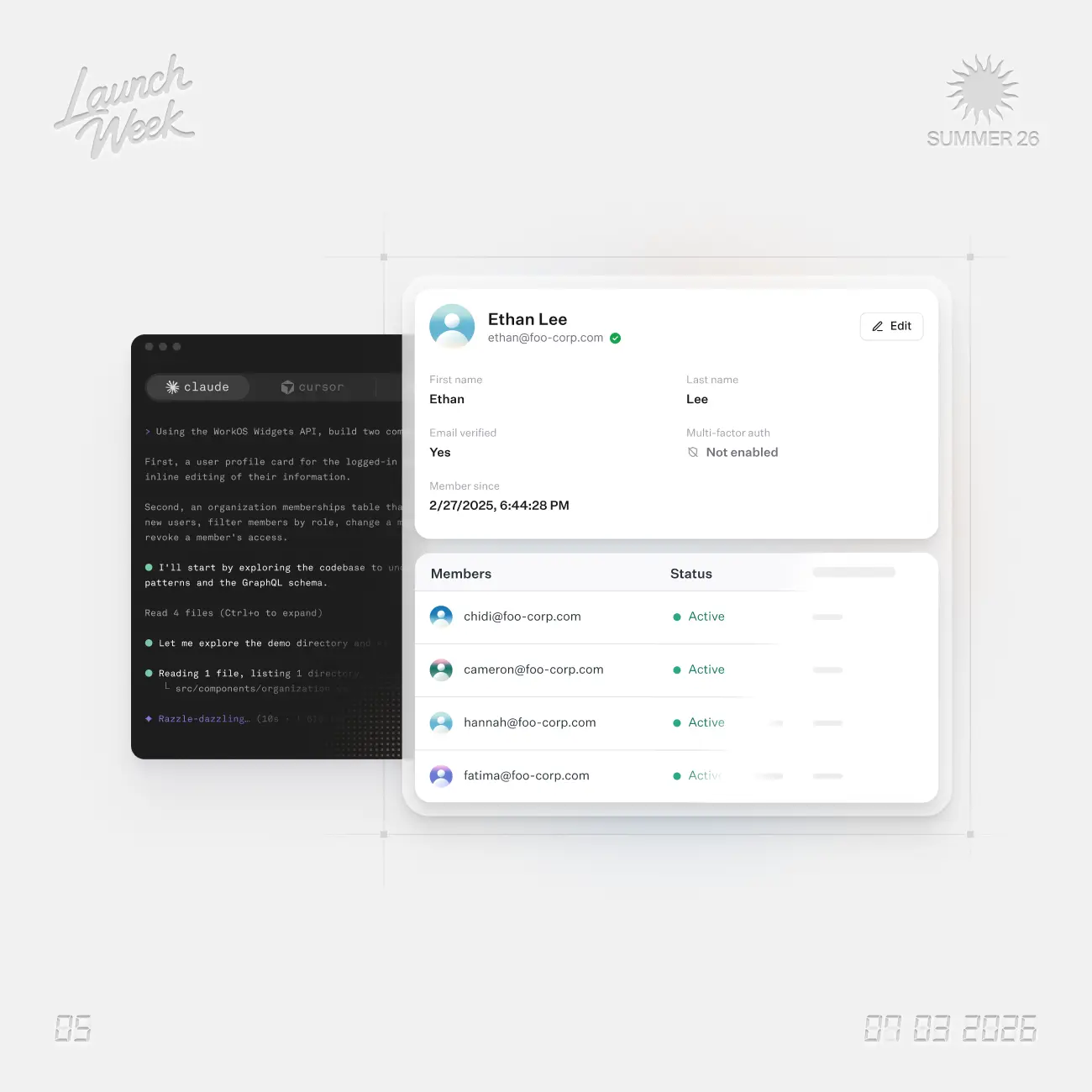
A session-aware GraphQL API for the browser, so you can build fully custom user management, admin panels, and more directly in your frontend.
We are launching a remote MCP server that gives AI agents the same access to WorkOS as your dashboard login.
A managed gateway that handles API key verification, token decoding, and authorization so your backend does not have to.
Vercel acquired Better Auth. If you run its SSO, SCIM, or enterprise plugins in production, here's the friction to weigh and how to decide whether to move.
Tailscale's Remy Guercio on Aperture, AI governance, and why the next 12 months of AI spend are about ROI maxing instead of token maxing, from AIE 2026.
Vercel is acquiring Better Auth. Here's what the deal changes for teams building on the open source auth library—and how to migrate your users to WorkOS.
A recap of WorkOS at the AI Engineer World's Fair 2026: an overflowing workshop, a founder mainstage talk, and two engineering talks on shipping with agents.
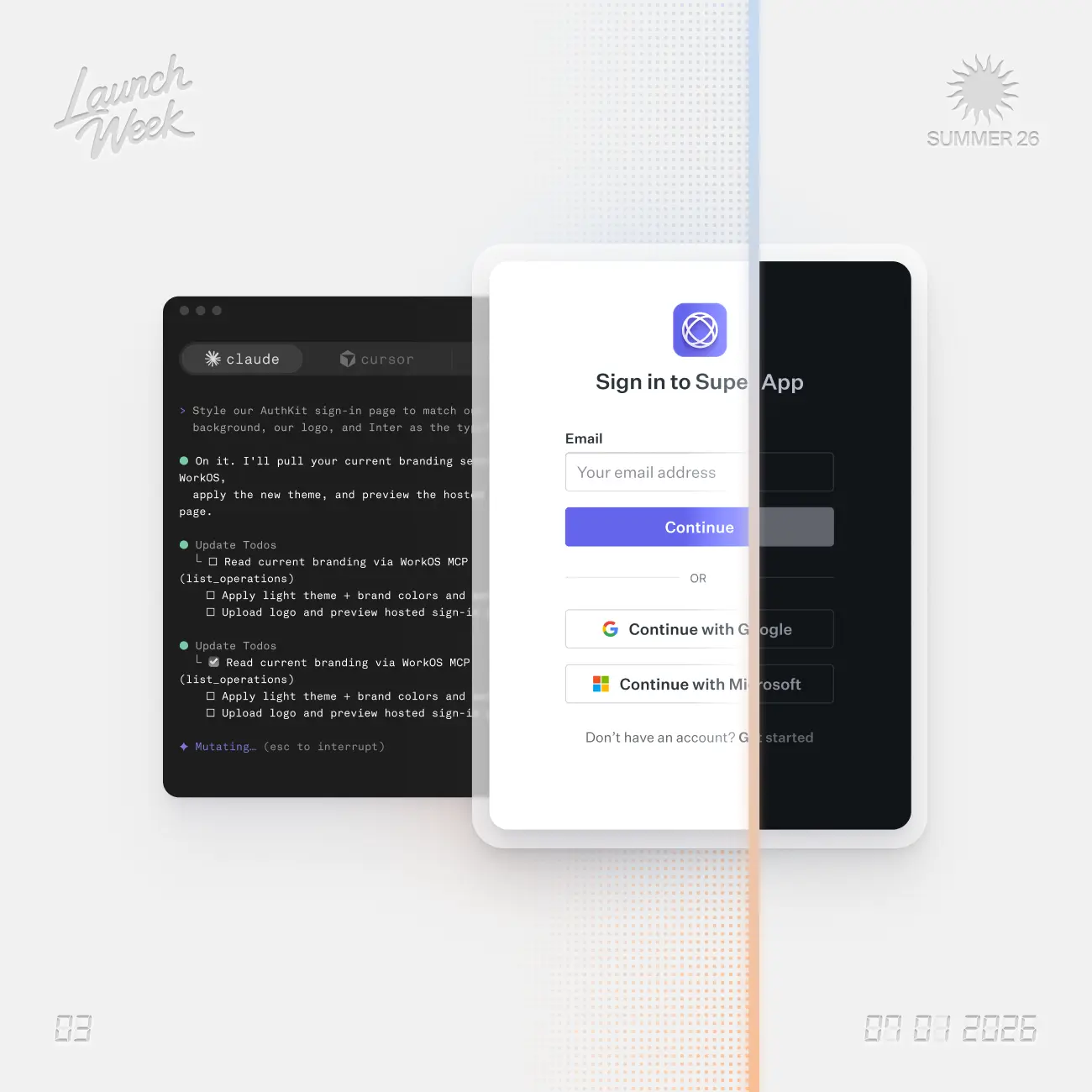
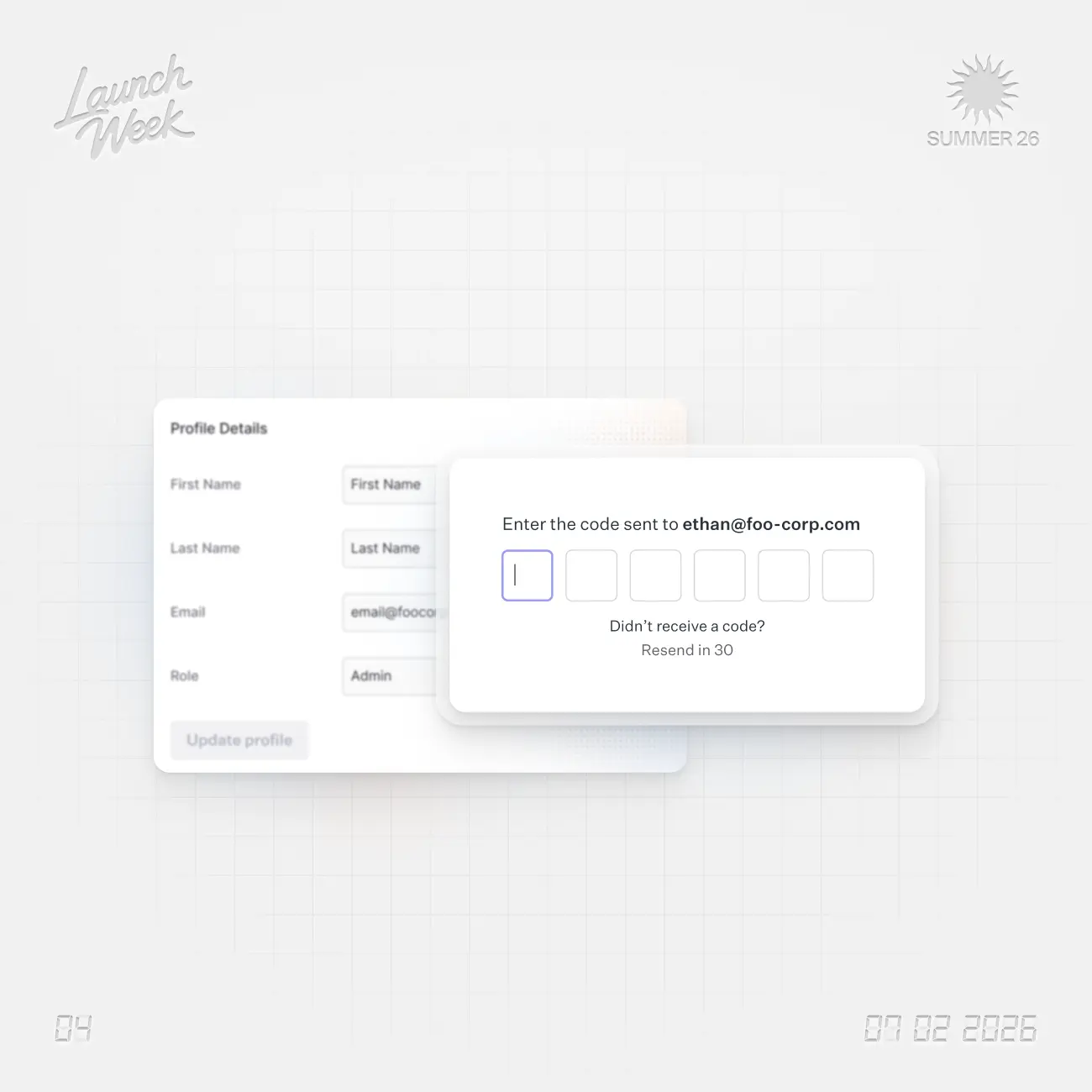
AuthKit can now require a user to re-authenticate before a sensitive action without ending their session.
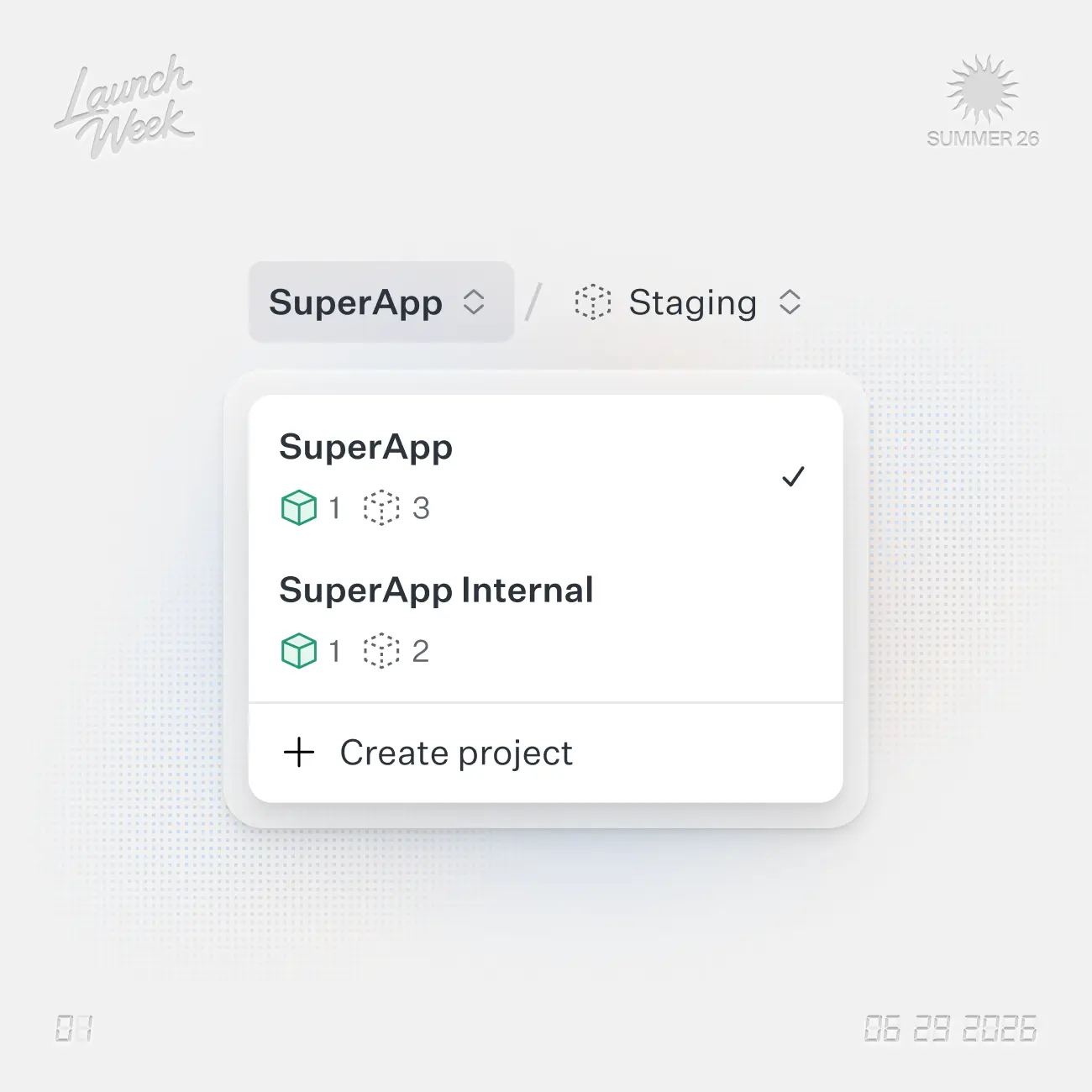
Group your environments by product and give each one its own branding, without separate WorkOS accounts.
A complete guide to social login in React Router v7, covering Google, GitHub, Microsoft, and every provider you will need as you grow.
Organizations are discovering that AI agent costs are invisible by design. The fix starts earlier in the stack than most teams realize.
How SAML attribute mapping works, how to configure it in Okta and Microsoft Entra ID, and how to map user roles, groups, and custom claims to your application.
AI agents are completing real purchases with real money. The fraud model, the liability model, and the authentication model all need to change.
On June 3, 2026, Cloudflare's CEO posted that bots had passed human web traffic for the first time. Here's what that actually means for your app, your API, and your analytics.
The MCP 2026-07-28 release candidate rewrites the protocol's foundation. Here's what's changing, what's breaking, and what your team needs to do before the final spec lands.
Please try a different search
Our global team is growing and we’re hiring all types of roles.
WorkOS builds developer tools for quickly adding enterprise features to applications.
We use cookies for analytics and advertising. See our cookie policy for details.




.webp)
.webp)
.webp)
.webp)
.webp)