Mazy Dar on building the future of video understanding at here
WorkOS CEO Michael Grinich interviews Mazy Dar, founder of Here, on building AI-native video understanding at HumanX 2026.
Most of the world's information lives in video — meetings, lectures, product demos, customer calls — and almost none of it is searchable. Text got its search engine decades ago. Video still lacks a comparable general-purpose solution.
WorkOS CEO Michael Grinich caught up with Mazy Dar, founder and CEO of Here, at HumanX 2026 to talk about what it takes to build an AI-native platform for video understanding and why the problem is harder than most people think.
The problem with video today
Video is everywhere, but it's essentially a black box. You can't search it, you can't skim it, and you can't extract structured data from it without watching the entire thing. For enterprises sitting on thousands of hours of recorded meetings, training sessions, and customer interactions, that's a massive amount of locked-up institutional knowledge.
Dar has spent years thinking about this problem. Before founding Here, he saw firsthand how organizations were drowning in video content with no good way to make it useful. Transcription was a partial solution, but it throws away everything that makes video valuable — the visual context, the tone, the presentation materials, the human signals that text alone can't capture.
What here is building
Here takes a multimodal approach to video understanding. Rather than just transcribing audio and calling it a day, the platform processes video holistically — analyzing visual content, speech, on-screen text, slides, and context simultaneously.
The goal is straightforward: make any moment in any video findable, quotable, and shareable directly into a workflow. Every video gets the same level of accessibility as a well-structured document, with the added richness that only video provides.
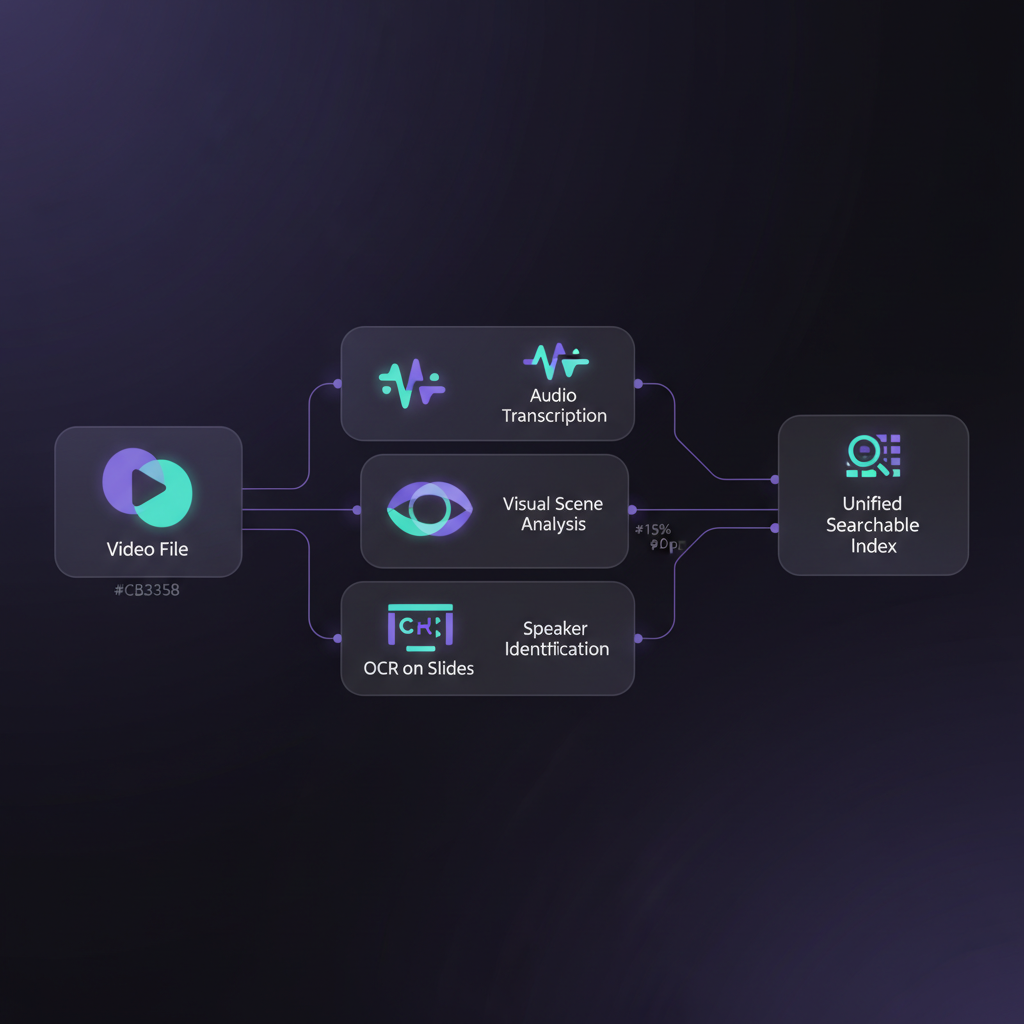
Why this is hard
Building a video understanding platform is fundamentally an infrastructure problem. Video files are large — a single hour of 1080p video can exceed a gigabyte — and processing them requires orchestrating multiple models in parallel. The results need to be fast enough that users actually get value from them in their daily workflow.
Dar talked about the engineering challenges of building at this intersection: the latency requirements, the cost of running multimodal inference at scale, and the challenge of making the output accurate enough that people trust it for real work. Getting to 90% accuracy is a demo. Getting to 99% is what makes it a product.
The enterprise opportunity
The conversation also touched on where enterprise adoption is heading. Companies are generating more video content than ever — the shift to remote and hybrid work accelerated that trend. But the tooling to manage, search, and learn from that content hasn't kept pace.
Dar sees a future where video becomes a first-class data source in the enterprise stack, as queryable and integrated as any database. That means APIs, integrations with existing workflows, and the kind of reliability and security — including access controls, data residency, and audit logging — that enterprise buyers demand.
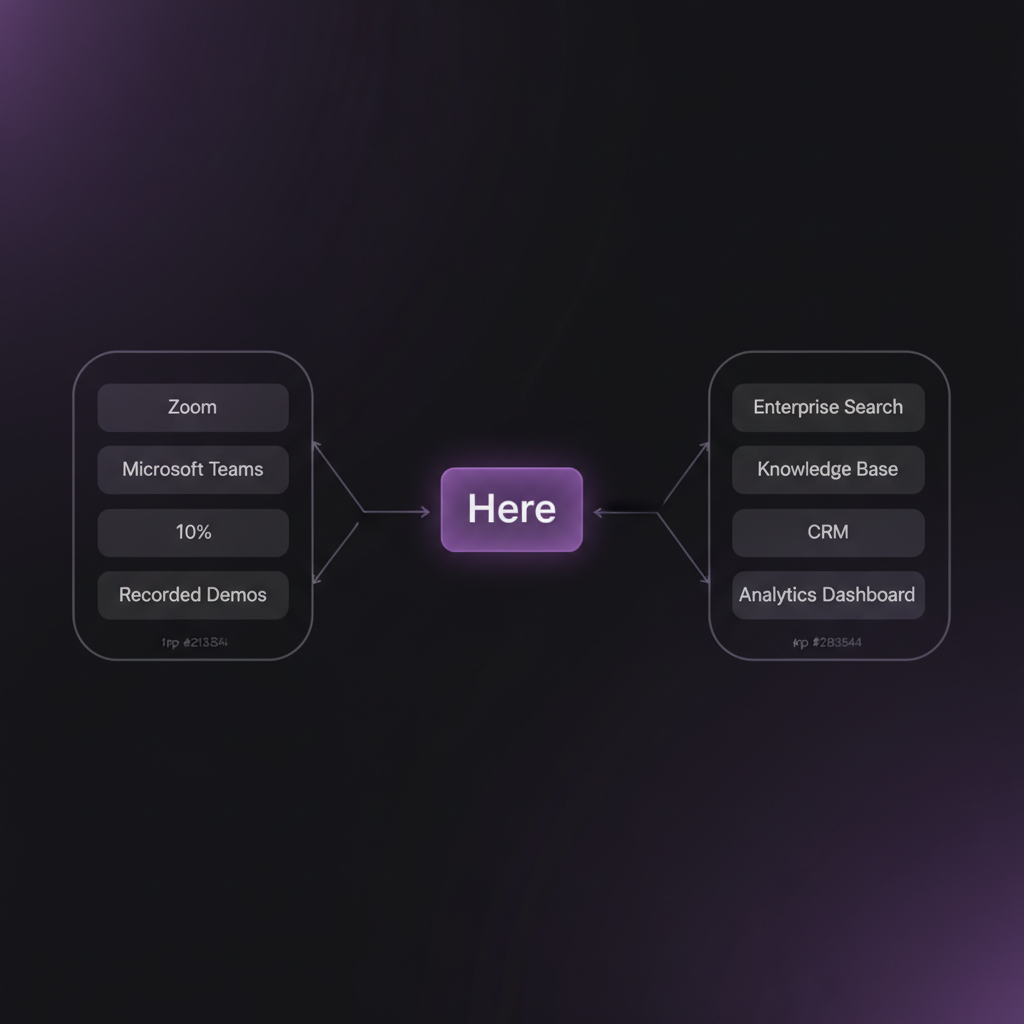
What's next for here
Dar and his team are focused on expanding the platform's capabilities and deepening enterprise integrations. The bet is that video understanding will become as fundamental as document search — and that the companies who build the infrastructure for it now will define the category.
For developers building products that touch video content, this space is worth watching. The gap between what's possible with multimodal AI in research and what's available in production-ready tools is narrowing as infrastructure matures.
Watch the full interview above for the complete conversation.
This interview was recorded at HumanX 2026 in San Francisco.