Why MiniMax M2.5 is the most popular model on OpenRouter right now
MiniMax M2.5 processes more tokens on OpenRouter than any other model. Here's why I use it as the chat frontline for my AI agent.
There's a model you've probably never heard of that's quietly eating OpenRouter alive. MiniMax M2.5 is the number one most-used model on the platform by token volume — over 2.45 trillion tokens processed in a single week as of February 2026 and counting. Chinese AI models now hold 61% of OpenRouter's market share, and MiniMax is leading the charge.

I've been running M2.5 in production as the fronting chat model for OpenClaw, my always-on AI agent running on a System76 Meerkat. It handles every conversational request that comes in. After weeks of real-world use, I want to share why I chose it, what it's good at, and where it falls short.
What MiniMax M2.5 actually is
M2.5 is a Mixture of Experts (MoE) model. It has 230 billion total parameters, but only 10 billion are active during any given inference pass. This is the key architectural decision that makes everything else possible — the model is simultaneously large enough to be capable and small enough to be fast and cheap to run.
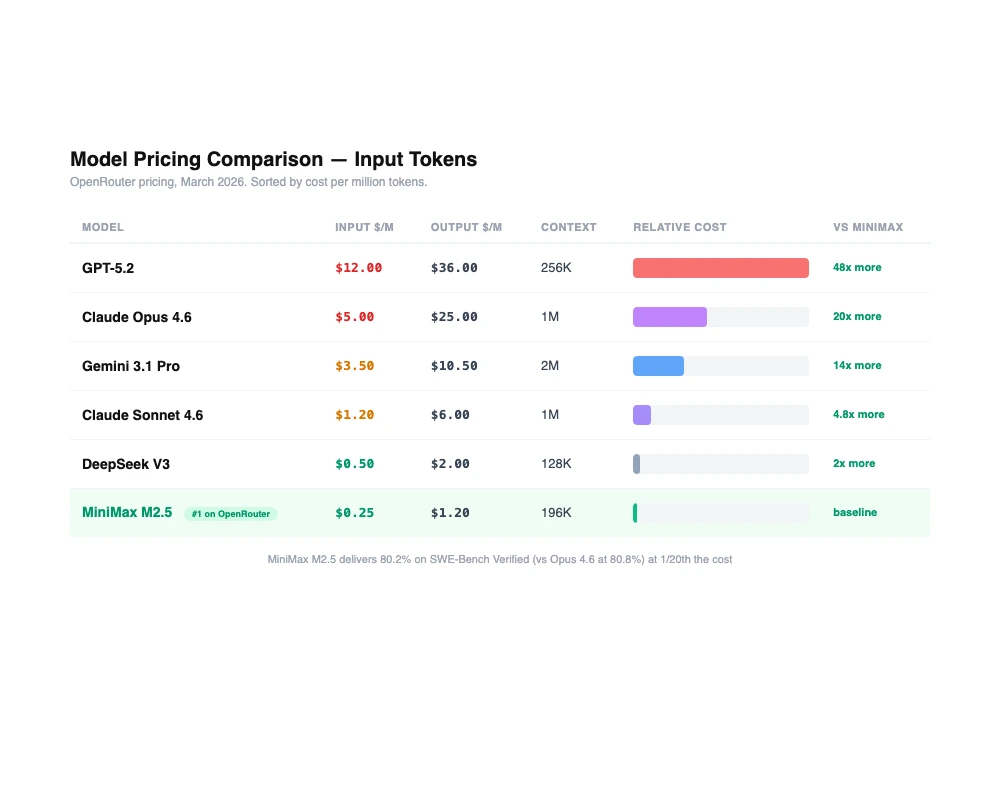
The pricing reflects this. On OpenRouter, M2.5 comes in two variants. The standard model costs ~$0.20 per million input tokens and $1.20 per million output tokens at 50 tokens/second. M2.5-Lightning doubles the speed to 100 tokens/second for roughly $0.30/$2.40."For comparison, Claude Opus 4.6 runs $5 per million input tokens. That makes M2.5 roughly 95% cheaper than Opus for equivalent tasks. VentureBeat called it "near state-of-the-art while costing 1/20th of Claude Opus 4.6," and that tracks with what I've seen.
The context window is 196K tokens — large enough for serious agentic work. Speed is solid too: 50 tokens per second on M2.5, 100 tokens per second on M2.5-Lightning. MiniMax reports it completes SWE-Bench tasks 37% faster than its predecessor, M2.1.
The benchmarks that matter
Here's where things get interesting. On SWE-Bench Verified, M2.5 scores 80.2%. Claude Opus 4.6 scores 80.8%. That's a rounding error's worth of difference on one of the most respected real-world coding benchmarks we have. Multi-SWE-Bench comes in at 51.3%, and BrowseComp at 76.3%.

Graham Neubig (OpenHands founder) put it bluntly: M2.5 is the "first open model that has exceeded Claude Sonnet on recent tests."
These numbers matter because they tell you M2.5 isn't just cheap — it's legitimately capable. The gap between frontier closed models and the best open models has narrowed to the point where, for many tasks, there's no practical difference.
Where it excels: the chat and agent frontline
M2.5 is exceptionally good at the work that makes up the bulk of most AI interactions: conversational chat, coding across languages, full-stack development, office productivity tasks, search and tool use, and agentic workflows.
In my OpenClaw setup, M2.5 handles all incoming conversational requests. It fields questions, manages tool calls, writes code across more than ten languages, and handles the kind of general-purpose work that would be absurdly expensive to route through a frontier reasoning model. It's fast enough that conversations feel snappy and capable enough that I rarely notice quality issues in day-to-day use.
MiniMax eats its own cooking here. Within their own organization, M2.5 autonomously completes 30% of all tasks across R&D, product, sales, and finance. Eighty percent of their newly committed code is M2.5-generated. That's a company betting its own productivity on the model.
Where it doesn't: know when to escalate
M2.5 is not the best model for everything, and pretending otherwise would be dishonest.
Deep reasoning is where Claude Opus still wins. When I need OpenClaw to work through a genuinely complex multi-step problem — architectural decisions, subtle debugging, nuanced analysis — I escalate to Opus. The quality difference is noticeable and worth the cost for those specific tasks.
Math is another weak spot. GPT-5.2 leads on mathematical reasoning benchmarks, and if your workload is math-heavy, M2.5 isn't your best option. Long-context multimodal work is where Gemini excels — if you're processing huge documents with mixed media, look there first.
The important thing isn't finding a single model that does everything. It's knowing what each model is good at and routing accordingly.
The tiered model strategy
This is the approach I've landed on for OpenClaw: M2.5 handles the bulk of conversational and chat work because it's cheap, fast, and good enough. Claude Opus handles reasoning tasks where depth matters. Claude Sonnet handles implementation work where you need reliable code generation without Opus pricing.
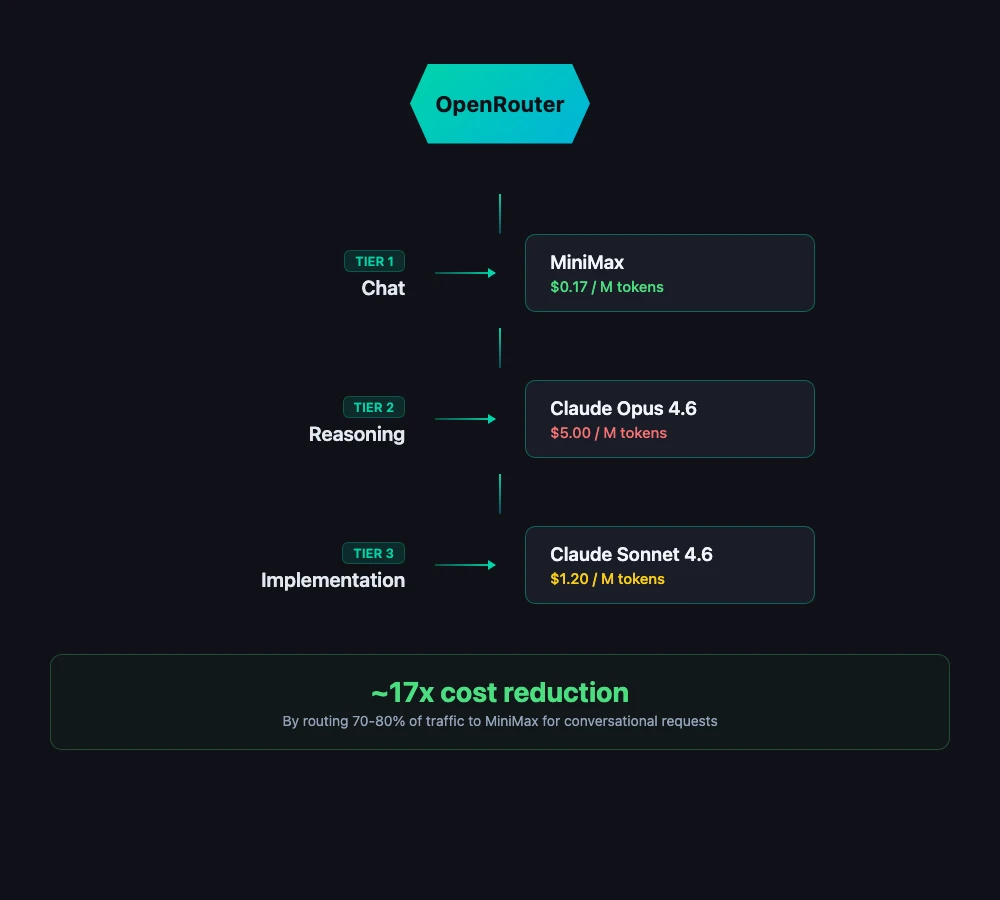
This tiered approach dropped my OpenClaw costs by 17x. Most AI interactions don't need frontier-level reasoning — they need a fast, capable model that can handle conversational flow, tool use, and general coding. M2.5 fills that role better than anything else I've tested at its price point.
I wrote more about this tiered model strategy and how I set it up in my post on building OpenClaw's model routing layer. The short version: don't pay Opus prices for Opus-level work when 80% of your requests can be handled by something 95% cheaper.
Why open weights matter
M2.5 is released under a modified MIT license and available on HuggingFace. You can download it, run it locally, fine-tune it, and deploy it on your own infrastructure. It runs on AMD hardware. No API dependency, no vendor lock-in, no usage-based pricing if you're willing to manage your own compute.
This matters more than most people realize. When your model is open-weight, you can audit it, customize it, and guarantee availability. You're not subject to pricing changes, rate limits, or sudden deprecations. For production workloads where reliability and cost predictability matter, open weights are a significant advantage.
What this means for the model landscape
The fact that a Chinese open-weight model is the most-used model on one of the largest AI routing platforms should make everyone pay attention. The moat around frontier closed models is getting shallower every quarter.
M2.5 isn't beating Opus at reasoning. It isn't beating GPT-5.2 at math. It isn't beating Gemini at long-context multimodal. But it's good enough at all of these things to handle the vast majority of real-world AI workloads, and it does it at a fraction of the cost while being open-weight and fast.
The winning strategy isn't picking one model. It's building a routing layer that knows when good enough is good enough and when you need to escalate to a specialist. M2.5 has earned its spot as the default — the model that handles everything until something harder comes along.
If you're still routing all your traffic through a single frontier model and wondering why your AI costs are through the roof, MiniMax M2.5 is worth a serious look.