How I dropped my OpenClaw cost of ownership 17x with OpenRouter
Running Claude Opus for every AI agent request was untenable. Here's how tiered model routing via OpenRouter cut costs 17x.
I love running autonomous AI agents. I do not love spending hundreds of dollars a month on API calls for what is essentially a fancy chat assistant that can also manage my files and run shell commands.
That was the situation I found myself in after a few weeks of running OpenClaw with Claude Opus 4.6 handling every single request. The quality was incredible. The invoice was not. Here's how I restructured things to cut costs roughly 17x without giving up the intelligence where it actually matters.
What OpenClaw is
OpenClaw is an open-source autonomous AI agent, originally created by Peter Steinberger, that runs on dedicated hardware and connects to messaging apps like Discord, WhatsApp, and Telegram. It's not a chatbot wrapper. It actually does things: runs commands, manages files, browses the web, handles email. Think of it as a capable assistant that lives on a machine you control.

I run mine on a System76 Meerkat, networked via Tailscale with Guardian handling security. It's a compact setup that stays on 24/7, fielding requests from various channels throughout the day. The hardware is cheap. The models powering it were not.
The Opus-for-everything problem
When I first set up OpenClaw, I pointed everything at Claude Opus 4.6. Every conversational message, every reasoning task, every implementation request -- all Opus, all the time.
At roughly $5 per million tokens, Opus is one of the most capable models you can use. It's also one of the most expensive. And when you're running an always-on agent that handles dozens of interactions a day across multiple channels, those tokens add up fast.
The thing is, most of those interactions didn't need Opus. Someone asks OpenClaw what time a meeting is? Opus. Someone wants a quick summary of a link? Opus. Someone needs a "sounds good, I'll handle it" reply drafted? Opus.
I was using a Formula 1 engine to drive to the grocery store.
The tiered model strategy
The fix was obvious once I stopped to think about it: not every request needs the same model. What I needed was a routing layer that could dispatch requests to the right model based on what the task actually demanded.
Enter OpenRouter.
OpenRouter gives you a single API endpoint that can route to dozens of model providers. More importantly, it lets you programmatically choose which model handles each request. That's the key piece. I wasn't looking for OpenRouter's auto-routing -- I wanted explicit control over which model handled what category of work.
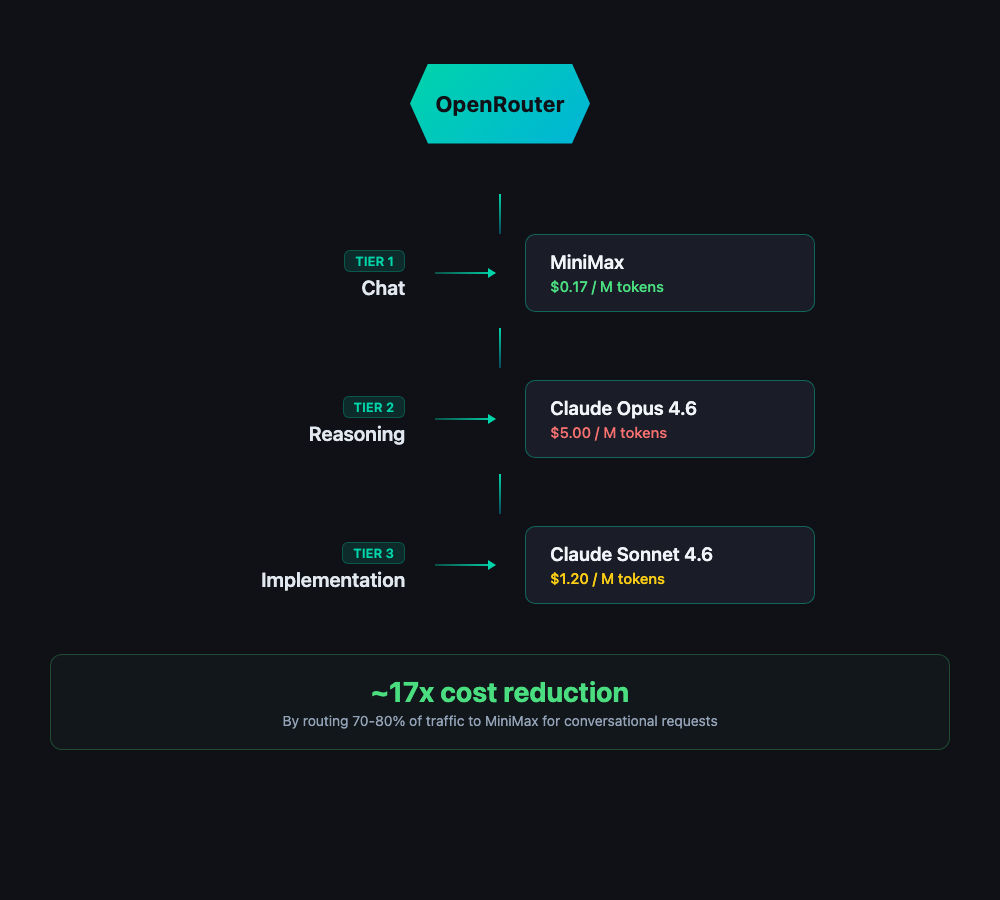
Here's the tiering I landed on:
Tier 1: Chat and conversational requests -- MiniMax
MiniMax is currently the most popular model on OpenRouter, and for good reason. At around $0.17 per million input tokens, it's nearly 20x cheaper than Opus. For conversational back-and-forth, quick questions, message drafting, and general chat, it's more than capable. This is the bulk of what an always-on agent handles, so this is where the savings pile up.
Tier 2: Thinking and reasoning -- Claude Opus 4.6
When OpenClaw needs to actually think -- complex multi-step reasoning, nuanced decision-making, anything where I need the model to be genuinely smart -- it escalates to Opus. These requests are a small fraction of total volume, but they're the ones where model quality directly impacts outcomes. I keep Opus in the loop for the work that justifies its price.
Tier 3: Implementation work -- Claude Sonnet 4.6 (1M context)
For longer-form implementation tasks like writing blog posts, generating code, or working through documents, Sonnet 4.6 with its million-token context window hits the sweet spot. It's significantly cheaper than Opus, handles long-context work naturally, and produces quality output for tasks where you need solid execution more than deep reasoning.
What changed
The cost difference was immediate and dramatic. Roughly 17x reduction in total spend.
The reason the multiplier is so large is simple math: the vast majority of interactions an always-on agent handles are conversational. They're the quick back-and-forth messages that don't need a frontier reasoning model. By routing 70-80% of traffic to MiniMax at a fraction of the cost, the overall blended rate drops through the floor -- even though I'm still paying full price for Opus on the tasks that need it.
Quality-wise, I haven't noticed meaningful degradation in day-to-day use. The conversations that were already simple stayed simple and still get handled well. The complex tasks that need Opus still get Opus. And the implementation work on Sonnet is consistently solid.
The one thing I did invest time in was getting the routing logic right. You need clear heuristics for what constitutes a "chat" request versus a "reasoning" request versus an "implementation" request. I started with simple keyword and intent-based rules, refined them over a couple of weeks, and now it's stable. The classification doesn't need to be perfect -- it just needs to be directionally correct. If a chat request accidentally gets routed to Opus, you waste a few cents. If a reasoning request gets routed to MiniMax, you'll notice the quality drop and can adjust.
The takeaway
If you're running autonomous AI agents -- whether it's OpenClaw or something you've built yourself -- the single biggest lever you have on cost is model routing. The idea that you need one model for everything is a holdover from when there were only a few models worth using. That's not the world we live in anymore.
The model landscape now has genuine options at every price point. MiniMax at $0.17 per million tokens is not the same as what budget models looked like a year ago. These are capable models that handle routine work well. And services like OpenRouter make it trivial to access them through a single integration point.
The pattern is straightforward: identify your workload tiers, match models to tiers based on the quality-cost tradeoff that makes sense, and route accordingly. You keep the expensive models for the work that earns their price, and you stop burning money on tasks that don't need it.
For me, that turned an unsustainable hobby-project cost into something I don't think twice about. And OpenClaw still handles everything it handled before -- it just got a lot smarter about which brain it uses for which job.