Service disruption on October 20, 2025
This post outlines the timeline and impact to our services and shares how we will improve resiliency for all WorkOS products starting immediately.
Starting on October 20 and continuing into October 21, WorkOS experienced service outages over two periods. The first period of impact began at 06:50 UTC and lasted until 09:20 UTC due to a AWS outage in us-east-1. The second period of impact began at 18:55 UTC and lasted until 01:50 UTC on October 21 due to subsequent cascading outages at critical vendors who provide hosting and feature flags.
We take full accountability for ensuring our services are provided without interruption, and we recognize that this incident failed to uphold this standard. Our mandate is to design and operate systems that account for all risks that affect availability.
This post outlines the timeline and impact to our services during this incident. Due to the severity of this incident, we are sharing how we will improve resiliency for all WorkOS products starting immediately.
How our systems responded
WorkOS offers multiple products that our customers may use independently or in composition. The impact on availability varied across our products — Directory Sync, for example, saw little disruption while Single Sign-On and AuthKit experienced significant outages.
Period of first impact
As AWS us-east-1 began to experience region-wide failures, our edge HTTP failure rate started to spike. In the logs below, the first bar of errors occurs at 06:50 UTC at which time engineers were paged.
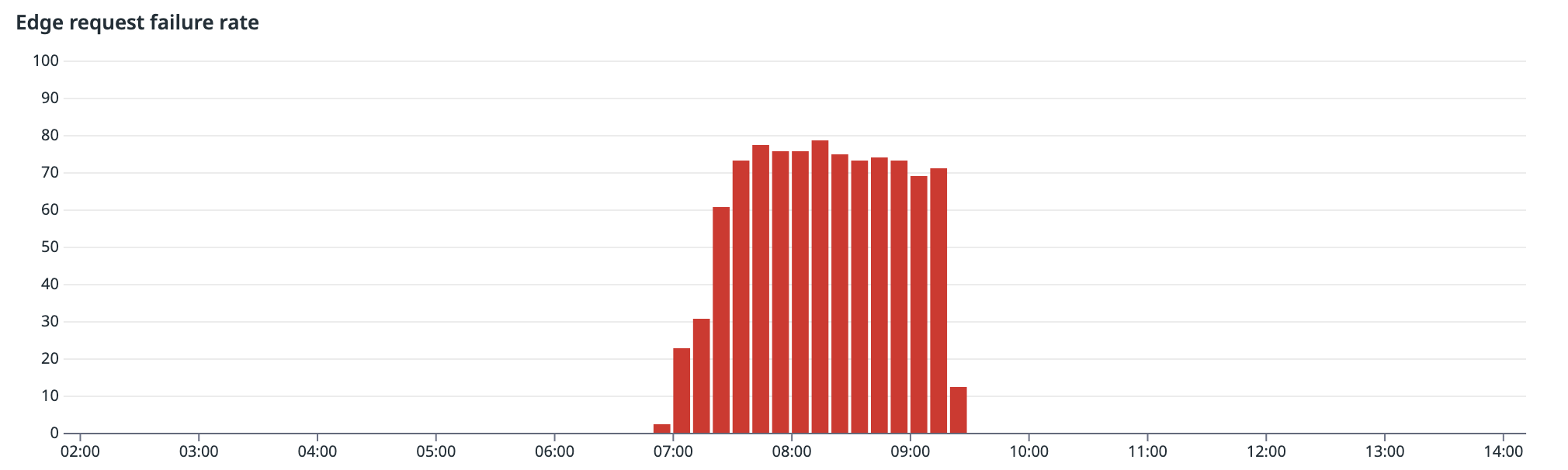
Single Sign-On was heavily impacted with a failure rate of 50%.

AuthKit was also heavily impacted with a failure rate of 100%.

Audit Logs was impacted with a failure rate of 30%.
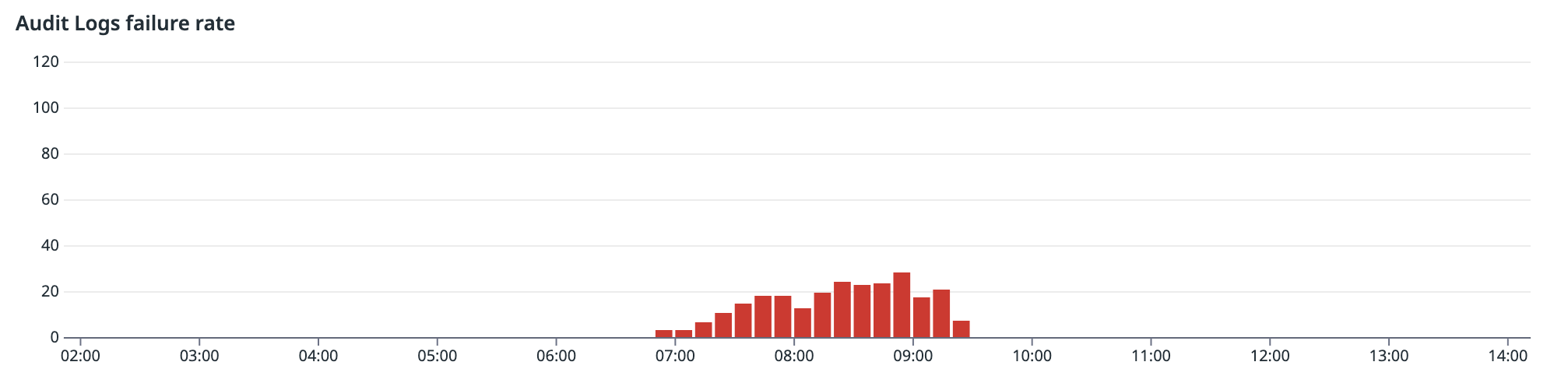
Admin Portal saw failure rates of 30%. Directory Sync saw a much lower failures rate at 2%. Sign-in for the WorkOS Dashboard was unavailable during this period while existing sessions were not impacted.
As the AWS us-east-1 region recovered at 09:20 UTC, service to all affected WorkOS products was restored.
Root cause analysis
Post-incident root cause analysis indicated the following technical failures led to service interruption.
- Within AWS, our database proxy was unable to establish new connections as it failed to retrieve database credentials due to IAM failures. As a result, certain product backends started to fail health checks and recycle their pods unsuccessfully. Variance in this behavior accounted for the different levels of error rates across products as shown above.
- AuthKit relies on a third-party hosting provider which was equally impacted by the AWS outage. At the time, we had not configured AuthKit to run in multiple regions for this provider.
Period of second impact
This period began at 18:55 UTC. Single Sign-On, Directory Sync and Audit Logs remained healthy. However, AuthKit, Admin Portal, and the WorkOS Dashboard were severely impacted.
The root cause for this outage was due to our feature-flag provider. Our efforts to mitigate were hindered by a concurrent incident with a hosting infrastructure provider. Both of these providers were still recovering from the earlier AWS us-east-1 regional outage that morning. These disruptions resulted in long request latencies and intermittent timeouts across AuthKit page loads, Admin Portal and the WorkOS Dashboard.
Approximately 70% of requests for these services failed during the peak of this period. Users experienced gateway timeouts loading hosted sign-in pages, and sign-in failures. Existing AuthKit sessions and session refresh functionality continued to operate normally.

Initial investigation attributed the cause to an active incident with our hosting provider. Our team attempted to redeploy AuthKit to a secondary region as a mitigation. This took extended time to execute due to deployment failures, and ultimately proved ineffective at restoring AuthKit availability. Observability data was also degraded during this time, limiting our ability to identify the root cause.
With the help of our hosting provider, our team determined the actual root cause was an incident with another third-party provider of feature flags. By 00:05 UTC on October 21, the team prepared a patch to switch the integration from streaming connections to polling, however service was not fully restored until 01:50 UTC due to ongoing deployment failures with our hosting provider.
Root cause analysis
The root cause was that our integration with our feature flag provider relied on default behavior in their SDK, which was not resilient to service unavailability. This resulted in hanging requests and caused the AuthKit pages to fail to render properly and return a 504 HTTP response.
Next steps
WorkOS will be implementing the following remediations immediately:
- Provide resiliency in the event of external provider outages by implementing appropriate timeouts, circuit breakers, and fallback logic.
- Deploying the AuthKit application layer to multiple AWS regions.
WorkOS is committing to the following remediations by the end of Q1 2026:
- Multi-region deployment of all WorkOS services in a hot standby configuration. This will enable WorkOS to be resilient to regional service failures and restore services within minutes.
- Architecting WorkOS authentication products to degrade gracefully and continue to serve requests when the primary database is unavailable.
Timeline (UTC)
Period of first impact
October 20, 06:50 Impact began with widespread errors across services.
06:59 Incident established.
07:19 Severity set to Critical. Initial data indicates an issue with database proxy.
07:29 Additional team members join incident response. Attempts were made to bypass the database proxy to restore service.
07:59 AWS confirms region-wide issues.
09:20 Impact ended as AWS services recovered and platform functionality returned.
10:08 Incident resolved; continued monitoring confirmed system stability.
Period of second impact
18:55 Impact begins.
19:12 Incident established.
19:22 Root cause was believed to be an outage with our hosting provider.
20:06 Severity updated to critical, additional team brought in. Attempted regional failover for AuthKit, but timeout behavior remained.
23:43 True root cause identified as an application integration issue with another third party provider.
October 21, 00:05 Fix tested and ready to deploy.
01:50 Fix deployed to production, after numerous delays due to issues with our hosting provider.