From 1.0.0 to 2025.4: Making sense of software versioning
Confused by versioning? This guide breaks down the top strategies to help you pick the right one, keeping your project organized and your users in the loop.
Version numbers. We see them every day—1.2.3, v4.0.0-beta, 2025.04, and beyond—but how often do we stop and think about what they actually mean?
Behind those dots and digits are decisions that shape how software evolves, how teams coordinate, and how users understand change.
In this article, we will break down the most common versioning schemes—SemVer, CalVer, and others—and explore how to choose the right one for your project (and when it’s okay to break the rules).
Why versioning matters
Version numbers aren’t just cosmetic. They communicate intent—to your team, your users, and your tools. A good versioning strategy helps with:
- Dependency management: Tools like npm, pip, or Cargo rely on version numbers to know what’s safe to install.
- User expectations: Is this a stable release or a breaking one?
- Communication: Teams use versions to coordinate releases and track changes over time.
Get your versioning strategy wrong, and you risk broken builds, confused users, and frustrated collaborators. Get it right, and your project becomes easier to use, maintain, and evolve.
Let’s see some real-world examples that show how important proper versioning is and what happens when people don’t follow best practices:
- In 2016, the JavaScript community learned a tough lesson about dependencies and versioning. A tiny npm package called
left-pad, which simply padded strings with spaces, was unpublished by its creator. Unfortunately, it was a transitive dependency for thousands of other packages, including high-profile projects likebabel. Almost overnight, CI builds across the world began to fail, because projects were relying on unpinned or loosely versioned dependencies. - The Log4Shell vulnerability (CVE-2021-44228) was one of the most critical Java-related security flaws in recent memory. It affected versions of Log4j between 2.0 and 2.14.1, allowing remote code execution via crafted log messages. For many organizations, the hardest part wasn’t patching — it was simply figuring out which version of Log4j they were using. This became even more complex when Log4j was brought in as a transitive dependency through another library.
- When the Babel JavaScript compiler released version 6 in 2015, it was a complete rewrite. Previously, Babel worked “out of the box.” But in v6, users had to install individual plugins for basic functionality like transpiling ES6. The Babel team did not provide a clear migration path or tooling for users upgrading from v5, and many developers simply updated their
package.jsonwith"babel": "^6.0.0"— resulting in broken builds and missing functionality. - The infamous Heartbleed vulnerability (CVE-2014-0160) affected OpenSSL versions 1.0.1 to 1.0.1f, allowing attackers to read memory from vulnerable servers — including sensitive user data. After the vulnerability was disclosed, many organizations scrambled to patch — but many didn’t know which version of OpenSSL their systems or Docker containers were using.
The list goes on, but you get the point. Proper software versioning matters. A lot.
SemVer (Semantic Versioning)
Semantic Versioning is the most widely adopted versioning scheme for open-source libraries, frameworks, and APIs. It’s strict, but powerful.
It follows the format MAJOR.MINOR.PATCH (e.g. 2.5.1).
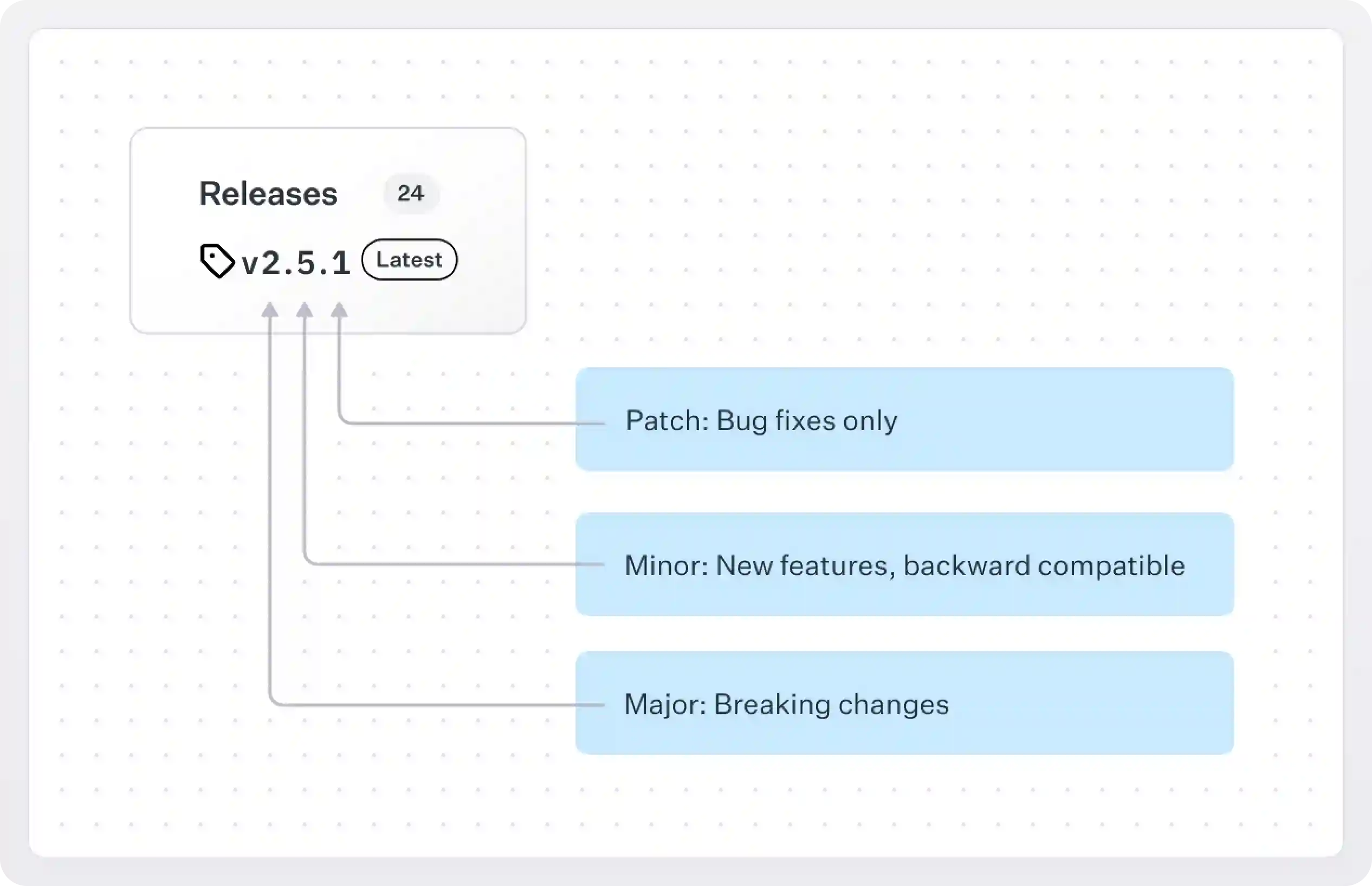
Here's what each part means:
- MAJOR version (
2.x.x): Bumped when you make incompatible API changes. Think of things like removing or renaming functions and changing behavior in a way that breaks backward compatibility. - MINOR version (
x.3.x): Bumped when you add functionality in a backward-compatible way. For example, adding new functions, endpoints, or features that don’t break existing code. - PATCH version (
x.x.1): Bumped when you make backward-compatible bug fixes. Things like fixing a typo, patching a security hole, or improving performance without changing the API.
SemVer also supports extra info:
- Pre-release versions are versions that come before a final release. They use a hyphen (
-) after the version, like:1.0.0-alpha,2.0.0-beta.2, etc. It’s commonly used when you want to release an unstable version to testers or early adopters. Some common labels are:alpha: early testing, not stable.beta: more stable, but still may change.rc(release candidate): pretty much done, unless something critical shows up.
- Build metadata is extra info used for tracking builds or internal versioning. It’s added with a plus sign (
+) at the end. For example,1.4.2+exp.sha.5114f85could be an “experimental build on version 1.4.2, based on commit5114f85”. You can use it if for example your CI/CD system builds your app every time you push a commit and you want to know which exact one came from which commit (even though all commits are for version1.0.0). You can use build metadata to differentiate your builds:1.0.0+build.1234: Build #12341.0.0+git.7c9d3e1: Commit hash1.0.0+20240415: Date
Let’s see how SemVer works in practice. Let’s say you’re working on a library that helps people do math:
- You release the first stable version. It includes basic functions like
add(),subtract(),multiply(),divide(). You tag the release as1.0.0. - You notice that
divide(10, 0)crashes the app. You fix it by returningInfinityor throwing a controlled error. This is a bug fix that doesn’t change the API, so you bump the patch:1.0.1. - You add a new method
power(base, exponent)to raise a number to a power. This doesn’t break anything, just adds new functionality. You bump the minor:1.1.0. - You realize that
divide()should return a float instead of an integer by default. This could break existing users’ expectations or code. That’s a breaking change, so you bump the major:2.0.0. - You're working on a big new feature, and you want to release a beta for testers:
2.1.0-beta.1. Once it’s stable, you release it as:2.1.0.
SemVer is a great choice if you're building a library, SDK, an open-source project, or anything with a public API that people depend on. It makes breaking changes explicit, and it's great for tooling and automated dependency management. On the downside, SemVer can feel “heavy” for fast-moving projects, and it's not ideal for apps where release timing matters more than change type.
Some software that uses SemVer is npm, Rust, and Go.
CalVer (Calendar Versioning)
Calendar Versioning ties your release number to time instead of change type. It’s common in tools, operating systems, and apps with frequent releases.
The format is YYYY.MM (e.g. 2025.04) or YY.MM.PATCH (e.g. 25.04.1).
On the plus side, CalVer:
- Is easy to understand: "Oh, that came out in April 2025".
- Matches predictable release cadences.
- Doesn’t require interpreting the type of change.
On the downside, CalVer:
- Doesn’t tell you if a release is breaking or not.
- Can feel meaningless for libraries.
This is how a product might be versioned over time using CalVer:
CalVer is a great choice if you're building an app, CLI tool, distro, or anything that releases on a set schedule.Here is some software that uses CalVer:
- Ubuntu Linux uses
YY.MM(22.04,24.10) - Android Studio uses
YYYY.X(2023.1,2024.1) systemd,pip, and others use it too.
SemVer vs. CalVer
Let's see how these two schemes compare:
Other schemes and hybrids
Let’s see some other schemes and hybrids that you can find online:
- ZeroVer (
0.x.x): Used during pre-release phases (pre-1.0 projects) and looks like0.x.x). According to SemVer, “anything may change at any time.” It’s a warning label for early-stage software. - Build Numbers / Internal IDs: You might see things like
v18394or1.4.102. These are often auto-generated by CI pipelines. Good for internal tracking, but not user-friendly. - Hybrids: Usually a mix of CalVer and SemVer. For example, Python uses Semantic Versioning-like version numbers in the form of
MAJOR.MINOR.MICRO— for example,3.12.2. However, Python’s release schedule is time-based, not strictly feature-based like SemVer. A new Python minor version (e.g.,3.12→3.13) is released once per year, typically in October. This gives it a calendar-like rhythm, similar to CalVer, even if the version number itself isn’t tied directly to the year (like23.10would be in true CalVer). - Named versions (code names): Each release has a memorable name instead of a number, e.g.,
Android KitKat,Ubuntu Bionic Beaver,macOS Ventura. The code name is often used alongside a version number behind the scenes. It’s a fun way to name releases, and good for marketing, but it doesn’t convey order clearly without a lookup. - Serial versions: Just a simple count of releases, like
1,2,3, etc. It has no minor or patch numbers. It’s used when there’s no need to indicate the change’s size or date—just order. You might encounter it in early versions of some games or some internal tools. - Project-specific custom versions: Some projects just say "nah" and make their own format:
- TeX: Uses a version number that converges to π (
3.141592...). - Java: Went from
1.4,1.5, then just called itJava 5, nowJava 21. - Emacs: Jumps from 27 → 28 → 29 with patch versions too.
- Firefox/Chrome: Super fast major version bumps, now on v120+.
- TeX: Uses a version number that converges to π (
How to choose the right versioning strategy
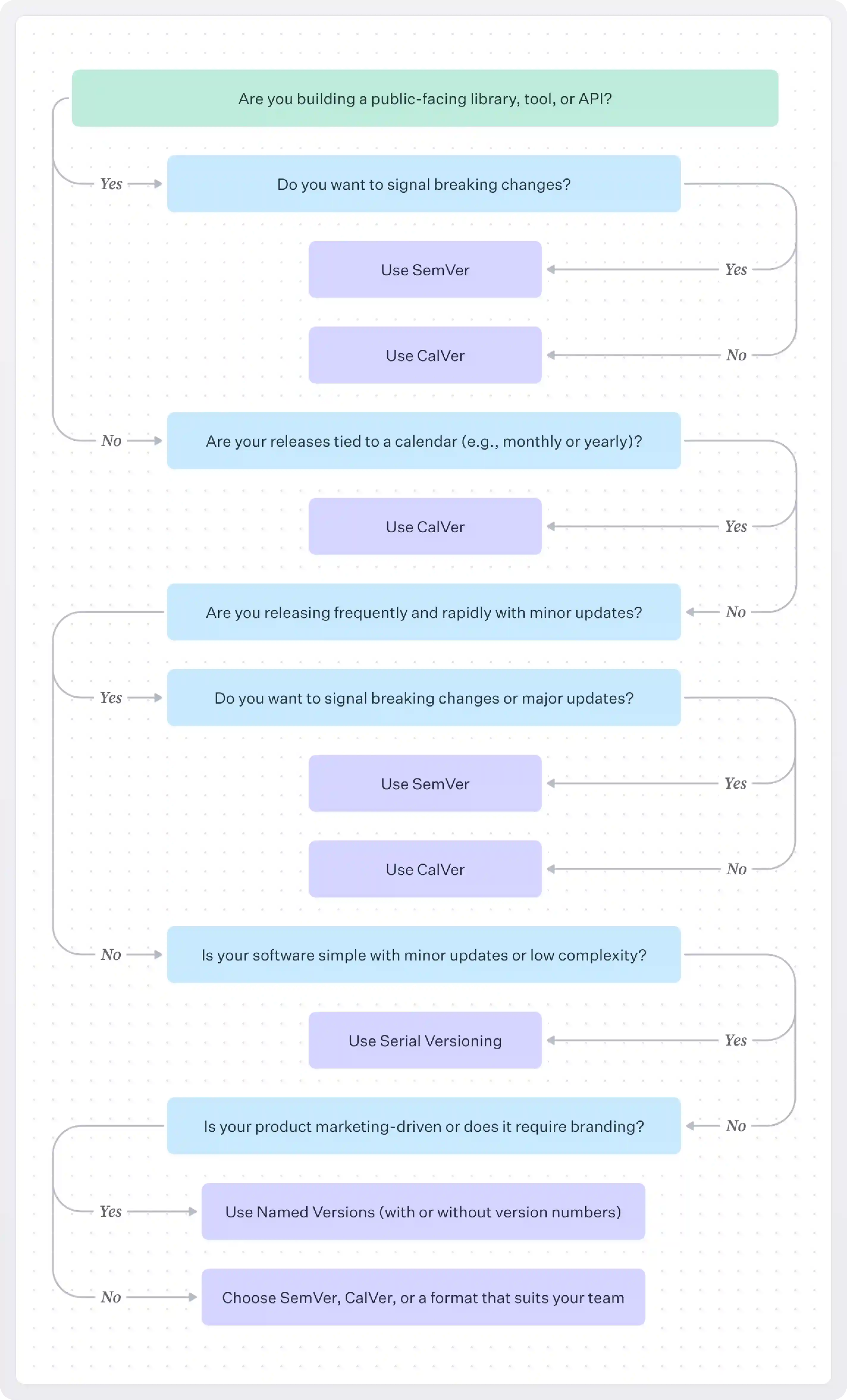
Choosing the right versioning strategy for your project depends on several factors, like the nature of your software, the development process, your user base, and how you want to communicate changes.
Here are some questions to help you decide.
Consider the nature of your project
- Is it a public-facing library, tool, or API?
- Go with SemVer. It’s perfect for public libraries or APIs where backward compatibility and clear communication of breaking changes are critical. This way, users and other developers can know if an update introduces a breaking change, a new feature, or a bug fix based on the version number.
- Example use cases: npm packages, Rust crates, or Python libraries. You have users depending on your software, so versioning based on compatibility is crucial.
- Is it a product or application that releases on a fixed schedule?
- Go with CalVer. If you follow a regular release cycle (like monthly, quarterly, or yearly), CalVer might be the best fit. It’s helpful when your users expect regular updates, and you want to indicate the release date rather than the specifics of backward compatibility.
- Example use cases: Ubuntu (releases every 6 months with versions like
20.04,21.10), Python (annual major versions like3.9,3.10).
- Is your product evolving with frequent updates and changes?
- Go with serial versioning (integer-based versioning). If the exact nature of changes doesn’t matter too much and you just want a simple way to increment versions, this might be useful for rapid development or internal tools.
- Example use cases: Internal tools, games, or applications that don’t care about backward compatibility.
- Is your versioning for marketing or branding purposes?
- Go with named versions. This is great if you want your product releases to feel more like events or you want to give them unique names. It’s often paired with actual version numbers, but the name itself is memorable.
- Example use cases: Android, Ubuntu, macOS, or large software products that use fun, memorable names like "Android Pie" or "Ubuntu Bionic Beaver".
Development and release cycle
- Are you releasing continuously or in rapid iterations?
- Go with CalVer or Timestamps. If you're rolling out updates frequently (e.g., weekly or monthly), and you care about showing when each release was made, CalVer is a great option. This makes it very clear to users when the software was updated and when they should expect updates.
Example use cases: Web apps, CI/CD pipelines, and Agile teams that work in short sprints and need to release regularly.
- Go with CalVer or Timestamps. If you're rolling out updates frequently (e.g., weekly or monthly), and you care about showing when each release was made, CalVer is a great option. This makes it very clear to users when the software was updated and when they should expect updates.
- Are you more concerned with stability and backward compatibility?
- Go with SemVer. It works best if your primary concern is maintaining compatibility with users' existing setups. If backward compatibility is important and you need to communicate major changes clearly, SemVer is designed for this purpose.
- Example use cases: Libraries and frameworks that need clear, predictable versioning for other developers to rely on.
Who are your users?
- Are your users developers who need clear versioning about breaking changes?
- Go with SemVer. It’s ideal for environments where developers rely on your library or framework, and need to know exactly when something might break their code.
- Example use cases: Open-source libraries, APIs, or SDKs used by developers. They’ll rely on knowing whether they need to make code changes when upgrading versions.
- Are your users non-technical or consumers who don’t care about compatibility?
- Go with CalVer or named versions. If your users care more about when the software was updated (rather than the specific changes), then a calendar-based approach (CalVer) or named versions can help. You’re focusing more on the when rather than what.
- Example use cases: Consumer applications, like games, mobile apps, or operating systems. They don’t care much about the technical details, just the freshness of the product.
Level of complexity in your software
- Is your software very simple with minor updates?
- Go with serial versioning. If your software is simple and the number of features/versions is relatively low, you can just use an integer-based approach to versioning (e.g.,
1,2,3). This is also a good choice for early development stages. - Example use cases: A small side project or prototype where you just want to keep track of versions without much complexity.
- Go with serial versioning. If your software is simple and the number of features/versions is relatively low, you can just use an integer-based approach to versioning (e.g.,
- Is your software complex with many major updates and breaking changes?
- Go with SemVer. For complex applications that undergo substantial changes, SemVer offers clear guidance on how to manage releases, especially if breaking changes are introduced. It's perfect for large-scale software where you need clear communication with users.
- Example use cases: Enterprise-level applications, libraries, or any complex project that requires detailed tracking of backward compatibility.
Flexibility for the future
- Do you need the flexibility to adjust your versioning strategy later?
- Go with SemVer or CalVer. These two are widely accepted and flexible, meaning you can change your strategy (e.g., switching from SemVer to CalVer or vice versa) later if your project evolves and needs a different approach. Both have broad adoption, so tools and ecosystems already support them.
TL;DR: Key factors for choosing your versioning strategy
Here is a summary of the factors that can drive your decision on which versioning strategy to use.
Versioning your API
When designing an API, versioning plays a crucial role in ensuring that the API can evolve without breaking existing clients. As APIs evolve, maintaining backward compatibility ensures clients aren’t forced to constantly update their integrations. Separating the API version from the application version helps create a stable API that remains usable across multiple versions of your application, even as you roll out new features.
Some common API strategies are:
- URL versioning: The version is specified directly in the URL path, such as
api.example.com/v1/. This is the simplest and most common approach. It’s easy to implement and understand but can clutter the URL with many versions over time.- Example:
GET /v1/users
- Example:
- Header-based versioning: The version information is passed in HTTP headers, keeping URLs clean. This method is more flexible for API consumers. You end up with cleaner URLs, but it’s less intuitive for developers new to the system.
- Example:
API-Version: v1
- Example:
- Content negotiation: The version is specified in the
Acceptheader, allowing clients to request different versions of the API based on content type. It’s flexible and clean, but more complex to implement and understand.- Example:
Accept: application/vnd.example.v1+json
- Example:
Deprecation and backward compatibility
As you continue to evolve your API, you may need to deprecate certain features or endpoints. The deprecation process is crucial for ensuring that your clients aren’t suddenly left without access to important features.
You should create a versioning policy for your API, which explains:
- When and why you’ll introduce a new version.
- How long previous versions will be supported.
- How clients should migrate between versions.
There are two ways to deprecate functionality:
- Soft deprecation: Mark features or endpoints as deprecated but continue to support them for several versions. You might mark an endpoint as deprecated in version
v2but continue supporting it in versionv3with a warning in the response. - Hard deprecation: Remove deprecated features after giving clients plenty of notice.
To ensure backward compatibility, additive changes (like new features or fields) should be made without breaking existing functionality. For major changes, introduce a new version of the resource or endpoint.
Versioning best practices
- Be consistent. Consistency ensures everyone (developers, users, tools) understands how to interpret your version numbers. Choose a versioning system (e.g., SemVer, CalVer) and stick to it throughout the life of the project. Don’t mix versioning schemes (e.g., don’t switch from SemVer to CalVer mid-project unless it’s a major change).
- Follow a clear versioning format. If you're using SemVer, make sure to follow the
major.minor.patchformat strictly. For CalVer, follow theYYYY.MMorYYYY.MM.DDformat to show when the release happened. - Version early and often. Don’t wait for big changes to bump your version number. Increment versions as you reach milestones, even small ones. This keeps the release history clean and clear, making it easier for developers and users to understand when updates happened. Adopt a versioning system that allows for frequent changes, especially for minor and patch releases.
- Avoid "no version" or "unversioned" releases. Always tag releases with a version number, even if it’s just for internal use or an alpha build. Without version numbers, users (and even your future self) will have trouble tracking what changed, and you might run into version conflicts down the line.
- Tag pre-release versions properly. For pre-release versions (e.g., beta, alpha, release candidates), always use the correct suffixes (
-alpha,-beta,-rc). This tells users that the release is not final and may still be unstable, and it also helps with dependency resolution in tools like npm, pip, etc. - Be honest: breaking changes deserve major bumps.
- Don’t over-commit to major version bumps. Avoid unnecessary major version bumps (e.g., changing
1.0.0to2.0.0) when the changes are minor. Frequent major version bumps can confuse users and make it harder to maintain dependencies. Only increase the major version if the changes break backward compatibility or are highly disruptive. - Use build metadata when necessary. Use build metadata (e.g.,
+build.1234,+sha.f1b2c3) to track specific build or commit details without affecting the version precedence. It allows you to track the specific version of the build without confusing users or changing the version’s meaning in terms of compatibility. - Document versioning changes. Maintain a clear changelog (e.g., a
CHANGELOG.md) that records all changes made in each version (major, minor, and patch). A changelog makes it easier to understand what changed in each version, and it’s especially helpful for open-source projects or teams working in parallel. Use conventional commit messages that indicate which type of changes are happening (e.g.,featfor new features,fixfor bug fixes,BREAKING CHANGEfor breaking changes). - Automate if possible (Git tags, CI). Use tools like semantic-release, standard-version, or release-it to automatically manage version numbers based on commit messages and changelog entries. Automation reduces human error and ensures consistency, especially when working in teams.
- Use versioning in dependencies. If you manage dependencies in your software (e.g., for a package or project), use version ranges to specify which versions of dependencies are acceptable, especially with SemVer. Proper dependency versioning ensures compatibility and reduces the chances of breaking changes. Examples:
^1.2.3— compatible with any1.x.xversion.~1.2.3— compatible with1.2.x, but not1.3.0.
- Handle deprecation clearly. If you're deprecating features, always signal it clearly in the changelog and with your version number. Clear communication about deprecated features and their removal helps users transition without breaking their setups unexpectedly. Remove deprecated features only after at least one major version (e.g.,
v3.x.x→v4.x.x). - Version numbers are immutable. Once a version number is assigned (e.g.,
1.2.0), never reuse it for a different release. Even if a bug is found, increment the patch version (e.g.,1.2.1), not the original number. Reusing version numbers can break builds, cause confusion, and mislead users into thinking that nothing has changed.
Software versioning FAQ
How do I handle breaking changes in my versioning scheme?
Breaking changes should be reflected in a MAJOR version increment in the versioning scheme, whether you're using SemVer, CalVer, or another approach. Here are some best practices:
- Communicate breaking changes clearly in the changelog.
- Offer a migration path or backward compatibility for existing users.
- For libraries or APIs, consider providing support for previous versions for a period of time before fully deprecating them.
Breaking changes should only be introduced when absolutely necessary, and careful planning should be done to ensure users have time to adapt.
How do I manage versioning in a microservices architecture?
In a microservices setup, each service can have its own independent versioning scheme. This means:
- Each service can release independently without affecting others.
- Clients can continue to work with older versions of a service while other services evolve.
Ensure that services that communicate with each other have clear version compatibility guidelines, and consider using contract-based testing to ensure different services interact correctly across versions.
How do I deal with deprecating old versions of my software?
When deprecating old versions:
- Provide clear notice to users about the upcoming deprecation (e.g., in release notes or notifications).
- Offer long-term support for deprecated versions, allowing users to transition smoothly.
- Implement a grace period where both old and new versions are supported.
- Remove support only after users have had enough time to migrate.
What is version skew, and how can I avoid it?
Version skew occurs when different components of your system are using different versions of the same service or library, leading to potential incompatibilities and errors.To avoid version skew:
- Use strict version management: Ensure that all dependencies are explicitly versioned in your
package.json,pom.xml, or similar files. - Centralized version control: Use a centralized package management system (e.g., npm, Maven, Docker images) to lock in specific versions of shared libraries and services.
- Automate upgrades: Automate the upgrade process of dependent components to keep them in sync across services and reduce the risk of version skew.
- Dependency auditing: Use dependency management tools to audit and track the versions of dependencies to avoid conflicts.
Example: If your backend services depend on an old version of a shared library, updating to a new version of that library across all services will help ensure compatibility and prevent bugs caused by version mismatch.
How do I handle cross-platform versioning in a multi-platform application?
In multi-platform applications (e.g., mobile, web, and backend), you might encounter different versioning needs. Here’s how to handle it effectively:
- Separate versioning for platforms: Each platform (e.g., iOS, Android, Web) should have its own versioning system. For example, the backend might use SemVer (
1.2.3), while the mobile app might use CalVer (2025.04). - Unified API versioning: If your application relies on a shared API, ensure that the API has a consistent versioning strategy that can be consumed across all platforms.
- Cross-platform compatibility: Make sure that changes to one platform don’t break others. For example, a new feature in the mobile app should not break the API consumed by the web application.
- Unified release notes: Maintain a central place where users can see the release notes across platforms, making it easier to track changes across the whole system.
Example: A mobile app (MyApp 1.0.0) may rely on an API that is versioned as v1.3.0. However, the mobile version could release new features monthly, whereas the API is updated quarterly, with careful coordination of release schedules to ensure compatibility.
How do I handle versioning in long-lived systems (e.g., embedded software or legacy systems)?
Long-lived systems often face challenges with versioning due to their extended life cycle and potential lack of frequent updates. Here are best practices:
- Long-term support (LTS) versions: Define LTS versions that focus on stability and backward compatibility for users who don’t need the latest features. You can maintain security patches and minor bug fixes for these versions for a longer period.
- Patch and security releases: For older versions, focus on patching security vulnerabilities and fixing critical bugs rather than introducing new features that could destabilize the system.
- Clear documentation: Maintain thorough documentation outlining which versions are LTS, which are supported with updates, and which have reached end-of-life (EOL).
- Deprecation strategy: Introduce a clear deprecation process, where you gradually phase out support for older versions while encouraging users to upgrade to more recent, secure versions.
Example: An embedded system might run a firmware version v1.0.0 for several years. However, each year it may receive security patches like v1.0.1, v1.0.2, etc., and a new major release, v2.0.0, may introduce new features or functionality.
How should I manage versioning in a monorepo?
In a monorepo (a single repository for multiple projects), versioning can get tricky because all components live in the same repository but may evolve at different rates. Here’s how to manage versioning:
- Unified versioning: All components in the monorepo may share a single version (e.g.,
v2.3.0), which simplifies versioning but might cause difficulties if some components evolve at different rates. - Component-specific versioning: Alternatively, version each component independently within the monorepo. This allows different components to evolve without forcing all projects to update together.
- Automation tools: Use tools like Lerna or Nx to help automate versioning and releases in a monorepo. These tools can help manage dependencies and determine which components have changed, allowing you to release only the affected parts of the codebase.
- Semantic changelogs: Ensure that the changelog clearly indicates which version corresponds to which component or service in the monorepo.
Example: In a monorepo with services like auth, payment, and notification, you might choose to version each service independently while keeping track of their changes in a unified changelog.
How do I manage versioning for a SaaS (Software-as-a-Service) product?
Versioning for a SaaS product can be complex because the software is continuously deployed to users. Here’s how to handle it:
- Release channels: Offer release channels (e.g., stable, beta, canary) to allow users to opt into newer versions with varying levels of risk.
- A/B testing: Use A/B testing to roll out new features gradually, ensuring that users can test new functionality before it becomes the default.
- Versioning the API: Ensure that the API versioning remains stable even as the frontend evolves. This allows clients to continue interacting with your API without worrying about breaking changes.
- Feature flags: Use feature flags to manage which features are enabled in which version, allowing you to experiment with features in production without affecting all users.
- Deprecation policy: Define clear timelines for when old versions or features will be deprecated and remove them only after giving users ample notice.
Example: A SaaS application might have a v3.0.0 version for its API but use feature flags to introduce a new UI only to a subset of users before fully rolling it out.
How do I handle versioning in distributed systems or serverless architectures?
In distributed or serverless architectures, versioning requires a slightly different approach:
- Lambda functions and microservices: For serverless services, version each function independently, using semantic versioning to manage breaking changes, and deploy them in isolated environments.
- Event-driven systems: When handling events, version the event schema to ensure that consumers can handle changes in the event format. Consider using a schema registry to enforce versioning and compatibility.
- Containerized environments: For containerized services (e.g., Docker), ensure that each version of the container image is tagged correctly, and handle versioning using the container registry tags (e.g.,
myapp:v1.2.0).
Example: A serverless function responsible for sending notifications might evolve over time, with new versions of the function tagged as v1, v2, etc., while ensuring backward compatibility with older versions for consumers still using them.
Closing thoughts
There’s no perfect versioning scheme—each comes with its own set of tradeoffs, and the right choice ultimately depends on your project’s goals, your team’s habits, and your users’ needs.
Whether you go with SemVer, CalVer, or another system, it’s important to pick one that aligns with how your team works and how you want to communicate changes.
When in doubt, start with SemVer—it’s widely adopted, clear, and flexible for many use cases.