Synchronous vs. asynchronous authorization updates: How to choose
Why we start synchronous, when we move to async, and why revocations are different.
A user gets added to an "Engineering" group. That group carries three role assignments across different resources. How fast do those permissions need to take effect, and what are you willing to pay for that speed?
This is the sync-vs-async decision for authorization updates, and getting it wrong means either unnecessary latency on every write or a window where users have stale permissions. Here's how we think about it on the WorkOS authorization team.
The core tradeoff
Synchronous means the API call that adds a user to a group also computes their new effective permissions before returning a response. The caller gets a consistent view immediately. The cost: every membership change now includes a role config fetch, a diff against existing assignments, and a write, all inline. For a single user with a handful of role assignments, that adds roughly 50 to 150ms of extra latency depending on your datastore and network topology. Manageable.
Asynchronous means the membership record is written immediately, and a background job reconciles the downstream role assignments. The API responds fast, but there's a window where the user's group membership and their effective permissions are out of sync.
Grants and revocations are not the same
The direction of the change matters as much as the scale of it. A delayed grant is a UX problem. The user clicks something, gets a 403 for a few seconds, refreshes, and it works. Annoying but bounded.
A delayed revocation is a security window. Someone you've decided shouldn't have access still has it for as long as reconciliation takes. That's a different category of problem, and it argues for treating revocations more conservatively than grants. In practice, this means either keeping revocations synchronous even after you've moved grants to async, or putting much tighter SLAs on the reconciliation job for revocation events. Keep that in mind moving forward.
When synchronous works
Sync is the simpler model. No job coordination, no eventual consistency semantics to explain to API consumers, no reconciliation edge cases. If your groups are small and role assignments per group are bounded, the inline computation is trivial.
We've found this holds when you can keep two numbers reasonable: group membership count and role assignments per group. With a ceiling of around 20 named roles per environment (which also keeps teams from drifting into the role-as-permission antipattern, where every individual capability becomes its own role) and group sizes under a few thousand, the per-request overhead stays well within acceptable latency.
The risk is write contention. If a background reconciliation job is processing a large group at the same moment an API call tries to add a member synchronously, they're competing for the same rows. In practice, the operations are fast enough that contention stays low, but it's the first thing to monitor.
When you need async
Multiply the numbers and sync falls apart. A group with 5,000 members and 5,000 role assignments means a reconciliation pass touches up to 25 million member-role pair evaluations. That can't live inside a request cycle.
The pattern we've landed on for large-scale reconciliation: a single background job owns the entire group and works through its members in batches, reading a page of members, computing and writing their role assignments, committing, then moving to the next page. One job, one group, start to finish. This mirrors how Directory Sync already works at WorkOS, one job per directory, iterating through all users sequentially. We deliberately avoided a fan-out pattern where a parent job spawns many child jobs. That coordination model introduces partial-failure states and retry complexity that might cause incidents; the single-job approach is boring and predictable, which is what you want from background infrastructure.
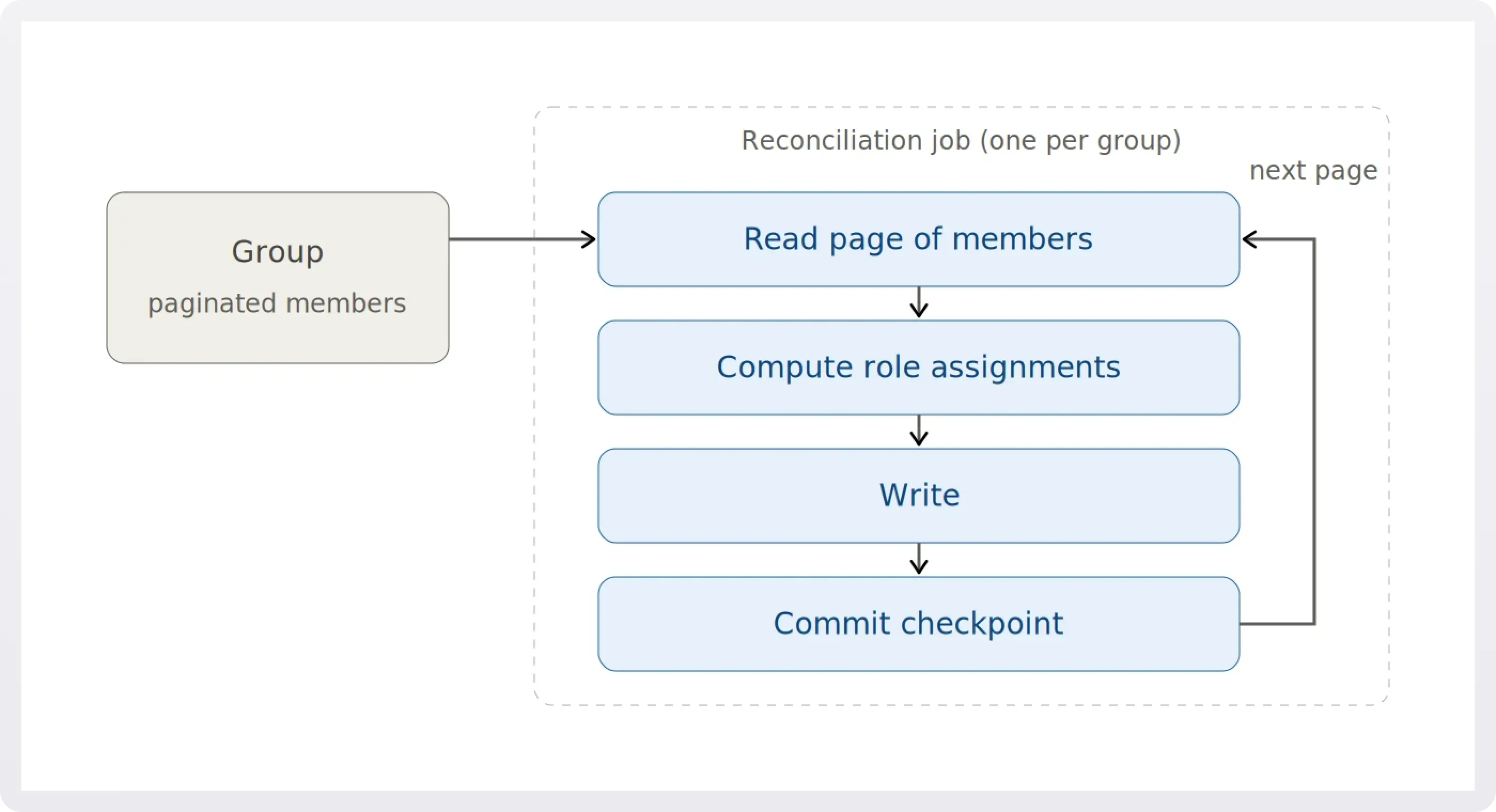
For that to actually be predictable, the job has to be idempotent and checkpointed. Each pagination step commits its progress, so a job that crashes halfway through a 5,000-member group resumes where it left off rather than restarting and double-applying assignments. We alert on jobs that exceed their expected runtime budget for a given group size, which is the signal that a group is stuck in a partial-reconciliation state and someone needs to look at it.
Handling the consistency window
The tradeoff with async is the consistency window: a user might be "in the group" but not yet have the permissions that group confers. Your application has two ways to handle this.
- Make the propagation delay imperceptible. For most grant flows this is enough; if reconciliation completes in a few hundred milliseconds, the user never notices.
- Check group membership directly as a fallback. This is more involved than it sounds, because the application needs to know which permissions came from which group in order to evaluate "would this user have access if reconciliation had finished?" That's a real cost in code complexity, and it's worth paying for high-stakes flows (anything involving payments, admin actions, or data export) but probably not for everything. We tend to use the fallback selectively rather than as a global pattern.
A decision framework
- Start synchronous. Measure the latency of your role computation inline: config fetch, diff, write. If p99 stays under roughly 200ms (the 50 to 150ms typical case plus headroom for tail behavior under contention) and your group sizes are bounded, ship it.
- Monitor two signals. p99 latency on membership change endpoints, and write contention rates during reconciliation.
- Move to async when either degrades. Use the simplest job model possible: one job, one group, paginated iteration, idempotent checkpoints. Optimize the job pattern only after you have real data on group sizes in production.
- Treat revocations differently from grants. The math on consistency windows changes when the cost of a stale read is unauthorized access rather than a 403.
The instinct to prematurely parallelize is strong. Resist it. A single sequential job that you understand beats a distributed fan-out that surprises you at 2 AM.
Build this on WorkOS
If you're working through these tradeoffs in your own product, this is the territory WorkOS is built for.
- Directory Sync streams groups and memberships from your customers' identity providers through a single API, so you don't need a separate connector per IdP.
- Directory Sync streams groups and memberships from your customers' identity providers through a single API, so you don't need a separate connector per IdP. Changes arrive via webhooks or the Events API, which is also handy for data reconciliation.
- RBAC gives you the roles, permissions, and assignments model this post is built around, with IdP-group-to-role mapping out of the box.
- FGA extends RBAC with hierarchical, resource-scoped access control, for when "what role does this user have?" isn't precise enough and you need "what can this user do on this specific workspace, project, or document?"
Sign up for a free WorkOS account and start with whichever piece fits your stack.