AI agents vs service accounts: Key differences and what to do about them
The reasons why IAM controls built for service accounts and API clients don't transfer to AI agents.
Until recently, when we talked about non-human identities (NHI) we meant service accounts and machine-to-machine API clients (so, pretty similar things). Now we also have AI agents. The instinct to file agents under the same heading is understandable; from an authentication perspective, an agent calling an API looks much like a service account calling an API. Both present a credential, both hit the same endpoint, both show up in the same access logs.
That surface similarity is misleading. AI agents differ from traditional NHIs along enough axes that treating them as a variant of service accounts produces real security and operational problems. The differences are not about volume or speed; they are structural, and they affect how you authenticate, authorize, audit, and revoke.
This article walks through the differences that matter most, with attention to where existing IAM assumptions break.
1. Behavior: Defined in code vs produced at runtime
The first and largest difference is what produces the identity's actions.

A service account's behavior is defined in code. If a billing microservice calls POST /charges, that line of code exists somewhere in a repository, was reviewed at some point, and gets executed when a specific control-flow path is taken. The set of API calls a service account can make is, in principle, enumerable from its source. Behavior changes only when code changes, which means it goes through a deploy pipeline with reviewers, tests, and rollback.
An AI agent's behavior is produced at runtime by a model interpreting natural-language instructions. Two consequences follow. First, the set of actions an agent might take is not enumerable in advance; it is a function of the prompts it receives, the tools available to it, and the model's interpretation of both. Second, behavior changes without code changes. A new system prompt, a new tool description, a new model version, or even a different turn in a conversation can produce different actions from the same identity.
Most existing NHI controls (code review, change management, allowlist analysis, behavioral baselining) assume the first model. They do not have a meaningful answer for the second.
2. Scope: Fixed at provisioning vs decided per request
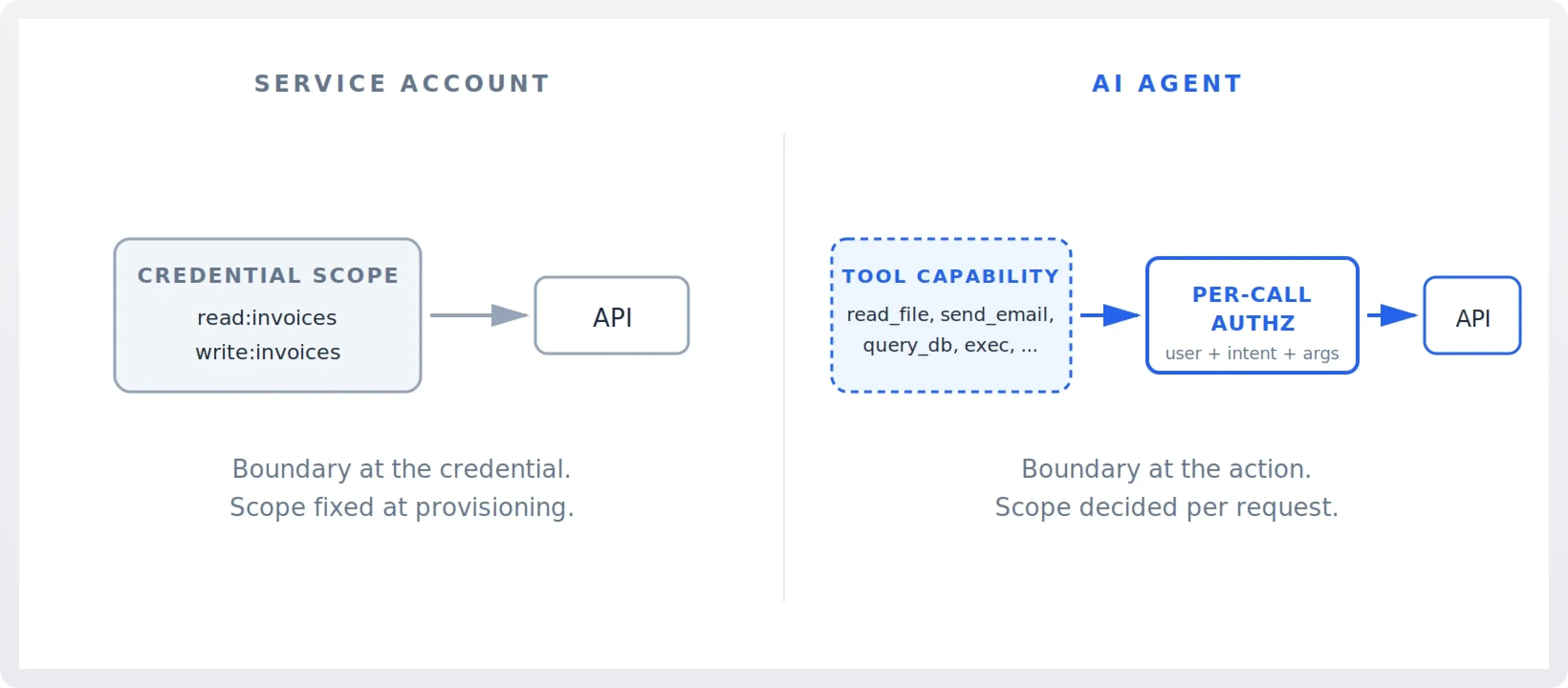
Traditional NHIs are typically provisioned with a fixed scope. A Stripe API key for a particular subaccount, a Snowflake service account with read access to one schema, a GitHub deploy token bound to one repo. Scope is decided at provisioning time, audited periodically, and rarely changes. Least privilege is hard but tractable, because the privileges and the work are both narrow.
AI agents are typically given access to a set of tools that spans what their users might plausibly need. A coding agent might have read/write access to a developer's entire repository graph, the ability to execute shell commands, and credentials to query internal services. This is not over-provisioning in the traditional sense; the agent genuinely needs broad capability because the requests it serves are open-ended.
The result is that the principle of least privilege has to move. It cannot live at the credential layer because the credential's scope is necessarily wide. It has to live at the moment of action, where a specific tool call with specific arguments is being authorized against the specific user request that prompted it. This is closer to dynamic, request-time authorization than to RBAC, and most identity systems are not built for it.
3. Identity: Who is the agent acting for?
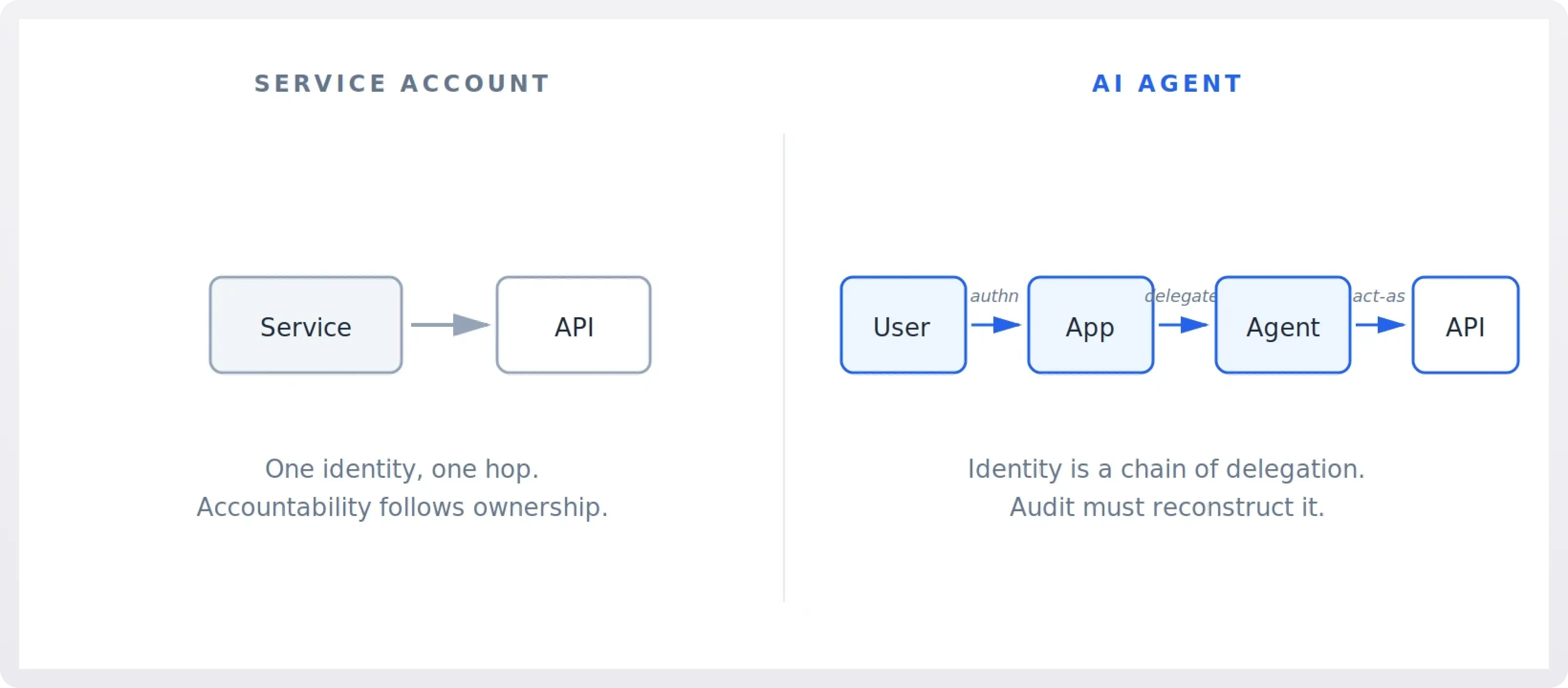
A service account acts as itself. When billing-service calls the payments API, the answer to "who is this" is "the billing service." Accountability follows ownership: a team owns the service, the service has an identity, the identity makes calls.
An AI agent typically acts on behalf of someone, and the chain has at least three links: the user who issued the request, the application or product the user is interacting with, and the agent process executing the work. In agent-to-agent setups it gets longer. Each link in this chain has its own trust assumptions and its own auditing needs.
This matters for two reasons. First, the right authorization decision often depends on which user the agent is currently serving, not on what the agent process is allowed to do in general. Second, when something goes wrong, "the agent did it" is not a satisfying answer; you need to reconstruct which user's session, which prompt, and which tool call produced the outcome. The identity model has to carry this provenance, not just the agent's own credential.
OAuth-style delegated tokens partially address this, and the emerging pattern of issuing short-lived, user-bound tokens to agents at session start is a real improvement over giving the agent its own long-lived credential. But it requires every downstream service to actually inspect and respect the delegated identity, which most internal services were not built to do.
!!For more on this, see AI agents and the multi-hop delegation problem.!!
4. Inputs as attack surface: Trusted instructions vs adversarial context

Service accounts cannot be socially engineered. You cannot get a cron job to wire money to a different account by emailing it persuasive copy. The input boundary is well defined: the service reads its config, takes its parameters, and executes.
AI agents have no such boundary. Any text the model processes is potentially an instruction. A user message, a tool output, a webpage the agent fetched, a document it summarized, a Jira ticket it read, an email in an inbox it has access to: all of these are inputs that the model may interpret as directives. This is the prompt injection class of issues, and it has no analogue in service-account threat modeling.
The implications for identity are direct. If the agent has the authority to take an action, that authority can be triggered by any party who can place text where the agent will read it. Effective security has to assume that the agent will at some point attempt something its current user did not ask for, and the question becomes whether the authorization layer below the model will catch it. This is the confused deputy problem, scaled up and made routine.
In practice this means authorization decisions for agent actions cannot rely solely on the agent's permissions. They have to factor in user intent (was this in scope of what the user actually asked for?), data provenance (did the instruction come from a trusted source?), and reversibility (is this action recoverable if it turns out to be unintended?). None of these are first-class concepts in current IAM systems.
5. Audit: Log lines vs reasoning traces
Auditing a service account is straightforward in shape, even when it is operationally hard. Each call has a caller, a target, a timestamp, and a result. To answer "why did this happen," you look at the code path that produced the call.
Auditing an agent action requires more. The minimum useful record includes the user request, the system prompt and tools available, the model and version, the chain of reasoning or tool calls leading to the action, the inputs the model considered, and the action itself. Without these, "why" is unanswerable, because the model's decision is not in any source file you can grep.

This expands what logs need to capture, and it raises real questions about retention, sensitivity, and access. Reasoning traces often contain user data, third-party content the agent processed, and sometimes internal credentials or hints about them. Treating these logs with the same casual approach as a service-account access log is a mistake; treating them with full sensitivity discipline is operationally heavy. Most teams have not picked a coherent answer yet.
Non-repudiation also changes. With a service account you can prove that an action was taken by the credential holder. With an agent you can prove that, plus you may need to prove that the action was within what the user actually asked for, which is a harder claim to support. Expect this to matter as agents start writing data, sending messages, and moving money.
6. Lifecycle: Provisioned credentials vs session-bound delegation
Service accounts have lifecycles measured in months or years. They are provisioned, rotated occasionally, and decommissioned when the service is retired. NHI inventory tools assume this cadence; they look for stale credentials, unused permissions, and aged secrets.
Agent identity tends to invert this. A well-designed agent system issues a fresh, narrowly scoped credential at the start of a user session, sometimes per task, often by exchanging a user's auth for a delegated token bound to that session. The credential exists for minutes and is gone. There is no stale token to find because they are all stale by tomorrow.
This is healthier from a blast-radius perspective, but it breaks tools that operate on the assumption of long-lived NHIs. It also pushes complexity into the token-issuance layer, which becomes a critical control point. A bug in token minting affects every agent session; a misconfiguration that grants slightly too much in the delegated token affects every subsequent call in that session.
The right mental model is closer to user session management than to service-account management, with the added complication that the "session" is not interactive in the human sense and may continue running unattended.
7. Tools as the actual permission boundary
In most agent architectures, the agent does not call APIs directly. It calls tools, which are server-side wrappers that translate model output into API calls. This layer is where most enforcement actually happens, and it is qualitatively different from anything in the service-account world.
Each tool has a name, a description shown to the model, a schema, an implementation, and a set of side effects. The description influences which calls the model attempts. The schema constrains arguments. The implementation enforces authorization, validates arguments, and executes against the underlying system. From an identity standpoint, "what the agent can do" is not its credential's permissions; it is the union of what its tools allow.
This has practical consequences. Adding a tool is closer to granting a permission than to deploying a feature. Tool descriptions are part of the security boundary, because they shape model behavior. Tool implementations need their own input validation against an adversarial model, not just against adversarial users. None of this maps cleanly onto traditional permission management.
What this implies in practice
A few patterns are starting to settle, and they look different from how organizations manage other NHIs.
- Authorize at the action, not at the credential. Per-tool-call policy evaluation, with awareness of the requesting user and the originating prompt, is the only place where meaningful least privilege can live for agents.
- Bind credentials to user sessions. Issue agent credentials by exchanging the user's authentication for a short-lived, narrowly scoped token. Avoid giving agents their own long-lived credentials wherever possible, and require downstream services to honor delegated identity rather than collapsing it into the agent's own.
- Treat tool inventories as permission catalogs. The set of tools available to an agent is the real description of its capability. Manage it accordingly, including review of new tools and their descriptions, and version them with the same discipline as IAM policy.
- Capture reasoning, not just calls. Logs that record only the API calls an agent made are insufficient for incident response. The prompts, tool inputs, and model outputs are part of the audit trail and need to be retained, secured, and made queryable.
- Plan for misuse via inputs. Assume that some fraction of the data the agent processes will contain hostile instructions. Design tool authorization so that an agent that has been talked into something cannot do too much damage with it, and prefer reversible operations or human-in-the-loop confirmation for actions that cannot be undone.
The category "non-human identity" is useful as long as everyone agrees it is a heterogeneous bucket. AI agents share the bucket with service accounts and API clients, but the controls that worked for the older inhabitants do not transfer cleanly. The teams that recognize this early will spend less time, later, untangling what their agents were allowed to do and why.
WorkOS for AI agents
WorkOS provides the identity primitives the patterns above depend on. AuthKit operates as a fully spec-compliant OAuth 2.1 authorization server for MCP, so agents and MCP servers can be issued scoped, short-lived tokens through standard flows rather than provisioned with long-lived static keys. Connect handles M2M authentication via the OAuth 2.0 client credentials flow when an agent genuinely needs its own identity. For agentic workflows, WorkOS Pipes lets you grant agents time-limited access to OAuth connections, scope tokens to specific tools, and enforce permissions so agents can only invoke what they have been authorized to use. Combined with enterprise SSO, directory sync, and audit logs, you get the delegation chain visibility that On-Behalf-Of flows are meant to provide.
If you are building agent features into a product and have started to feel where service-account assumptions stop working, start with AuthKit or talk to us about agent identity.