The developer’s guide to Fine-Grained Authorization (FGA)
As apps have become more complex, especially with the rise of user-generated content, the need for a more granular and scalable authorization scheme has become crucial. Unlike other models, Fine-Grained Authorization defines permissions at the resource level, providing precision and the ability to handle millions of authorization requests per second.

Most developers are familiar with RBAC, or Role-Based Access Control – it’s the old school standard for how authorization is built. Each user has a role, each app section has a permission, and you check on every action or page load to make sure that the currently authenticated user has the right to do what they’re doing.
But as apps have gotten more complicated – and supported more user generated content – teams have been focusing on a newer, more granular, and more scalable authorization scheme: Fine Grained Authorization. Fine Grained Authorization (FGA) defines permissions on a resource basis – individual users having access to individual resources. You can define precisely who can see or do what, down to individual fields in a database or specific actions in an application.
FGA is powerful – it supports millions of authorization requests per second for apps like YouTube and Google Drive – but it’s also notoriously difficult to implement yourself. This post will walk through what you need to know to get it done, from your data model to 3rd party options and UI considerations.
FGA basics – the data model
At the core of FGA is the relationship between a user and a resource. A resource is what the canonical object in your application is: a cap table for Carta, a bank account for J.P. Morgan, or a document in Google Drive, or a file in Figma.

The relationship field is highly dependent on your business: it could be as simple as `read` or `write` or as complex as `edit_maximum_of_5_rows_during_the_day`. This type of FGA relationship data is very difficult to represent efficiently in a relational database, and tends to be a much better fit for a graph model.
In practice, you don’t need to enumerate every possible permutation of user and resource in your system. FGA systems will also make use of roles, especially to assume default states. For example, you might have a group called “Airtable Admins” who have default permissions to every single Airtable base in the organization. In essence, people like to define their permissions through groups and roles, but check them at the user level.
Building resolver logic
Where the FGA data model gets complicated is what we call “resolvers” – all of the cases where a relationship isn’t explicitly coded into an authorization check, but is implied by other existing roles or hierarchies. You will need to write custom logic to resolve these yourself. Let’s run through a few examples.
Consider some basic hierarchy:
- You are part of the Airtable Admins group
- The Airtable Admins group is an owner of Top Secret Base
- Ergo, you are an owner of Top Secret Base
In an RBAC system, you being in the Airtable Admins group would mean that you pass the check to own Top Secret Base. In an FGA world though, it goes a level deeper, almost like a compiler or resolver: because you are in the Airtable Admins group, that means that you are personally an owner of Top Secret Base, and that’s why you pass the check. So this is logic that you need to write.
Another example: imagine a simple Google Docs authorization hierarchy. I set access to my doc such that everyone in my organization has comment access. Even though I haven’t shared the doc individually with my coworker, since she is part of my organization, my system needs to calculate that she, individually, has comment access to the doc. This kind of resolver is simple enough to build.
Next part. A Google Doc has the concept of an owner, an editor, and a viewer. An owner implies that you’re also an editor, which implies that you’re a viewer. This notion of permission inheritance is another “resolver” related thing that you will need to build yourself.
These two ideas – inheritance between roles, and inheritance between permissions – are the two big pieces of building a resolver system. If you can get these implemented, most other cases will fall in line. But you will likely find that edge cases from your customers make these things take much longer than they should, especially at scale.
Centralized vs. decentralized FGA
A central (🫣) piece of discussion in authorization is building centralized systems vs. decentralized ones – should your authorization system be its own service? There are two pieces to this: the data storage can be centralized or decentralized, and your check system can be too.
In an RBAC world, most teams don’t need to worry about services for a while. The scale of data is inherently smaller, you can scale to even millions of rows without much of a hiccup, and many developers are just shoving roles and permissions into a JWT anyway. FGA, on the other hand, tends to lend itself more to a centralized architecture (i.e. its own service) for a couple of reasons.
The first is that if your customers have the kinds of complex requirements that call for building out an FGA system, chances are you’re further along in your company journey and might have already split out your architecture into a service based one. And you certainly don’t want to replicate your check logic for every single service.
The second is that the FGA data model is inherently more inclined towards large data volumes than RBAC, and if you’re building it yourself, at some point you will necessarily need to move it into its own database so it can scale independently. This, plus the fact that these relationships are more naturally represented in a graph database, which in all likelihood is not the kind of database you’re using for production.
In practice, whether teams choose to centralize or decentralize this tends to depend more on their existing architecture. But FGA definitely lends itself more to a centralized implementation.
Outsourcing FGA (open source or otherwise)
Tons of teams will implement RBAC on their own. FGA, given how difficult it is, less common. And until a few years ago, there weren’t a ton of options for outsourcing.
Google Zanzibar is Google’s internal authorization system: it supports millions of authorization requests per second for products like YouTube and Drive. In 2019, they released a paper at USENIX that ran through how it works. To quote Carta’s AuthZ blog post, which has a nice summary:
One of Zanzibar’s core features is a uniform language that is used to define permissions. Zanzibar consumers use the uniform language to build Access Control Lists (ACLs). ACLs are like unix file permissions. They give users access to individual resources in the system. With Zanzibar, services compose abstractions for user permission groups. User permission groups can compose each other. They also grant access to low-level resource ACLs.
So essentially, it’s implemented as a centralized service that handles both the data and the resolvers. Since the 2019 paper, several open and closed source implementations have popped up on the market. You now have a bunch of options for “buying” FGA, like:
- WorkOS FGA (built on Warrant)
- SpiceDB (OSS) from Authzed
- OpenFGA (OSS)
You can pick OSS FGA systems off the shelf, but it only solves a part of the problem, since at scale these things are major operations to run. If you’re at a company like Figma, you’ll still need a 3 person team to manage this for you. You need to provide and manage a database, maintain performance, and keep the high uptime and availability that a centralized system needs.
I would also be remiss if I didn’t mention Open Policy Agent. It’s a framework for writing and evaluating policies for authorization. But OPA doesn’t have any data; it’s just policies. It’s like you’re running a function, but you need to provide the input at runtime. So I wouldn’t consider it a solution (in the traditional sense of the word) for completely building FGA. The Zanzibar model is a more natural fit for these business app type use cases, whereas OPA is really good for infra authorization (e.g. only allow ingress from this IP).
Frontend / UI considerations
FGA has a few considerations to mention when it comes to building UI for your users to set and adjust these permissions. You’ve probably seen this bad boy before:
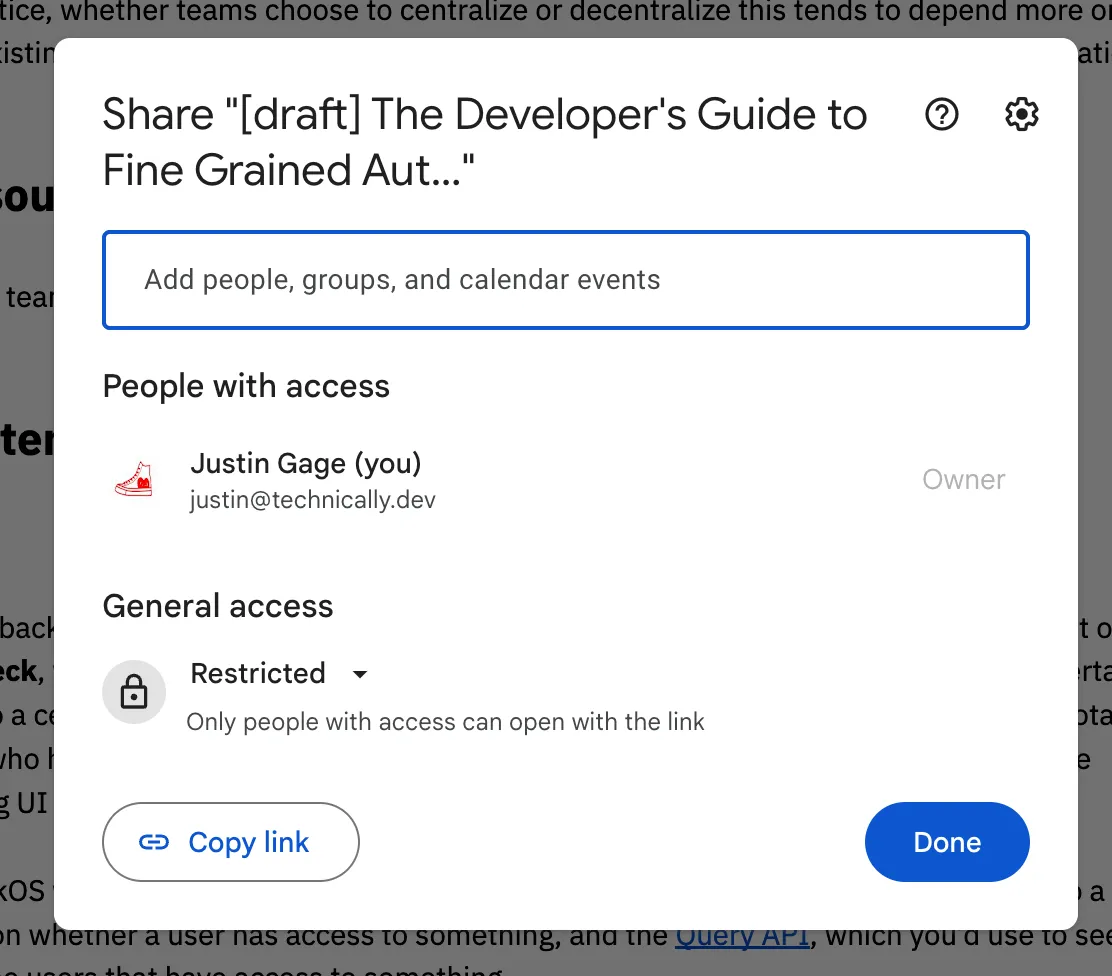
In an FGA universe, your users need to be able to share any resource with any individual user or group, plus see (and adjust) which users currently have access. That’s this screen:

On the backend, this expresses itself as two different types of queries. There’s the concept of the check, which deals with whether (in a boolean sense) a user has permission to do a certain thing to a certain resource. But there is also the concept of the list, which deals with the total set of who has what permissions to this resource. The list is the data you want when you’re building UI for users to be creating and updating these permissions in the first place.
In WorkOS we have these two APIs split out. There’s the Check API, which you’d use to do a check on whether a user has access to something, and the Query API, which you’d use to see all of the users that have access to something.
Bonus: FGA and Identity Providers
If you have customers large and sophisticated enough to be requesting authorization features that have you wondering if you should look at FGA, there’s a 90% chance they will be running their identity and access management through an Identity Provider (IdP) like Okta. These IdPs are the central source of truth for who works at these organizations, how they authenticate, and what they have access to.
RBAC plays nicely with these IdPs; FGA does not. The fundamental concept of resource-based authorization doesn’t really work well with IdP-based authorization at all. FGA is dynamic: I just created a new Figma file, I just built a new Hubspot contact list, and here’s a project ID. There’s no way an IT admin would be able to interpret all of these and apply the appropriate groups and roles.
We are guessing that things will go towards a hybrid RBAC/FGA direction in the future. If you’re interested in learning more about how these ideas interact with IdPs, check out our Developer’s Guide to RBAC and IdPs. It runs through a few best practices for setting up the FGA/role architecture on your end to work well with Okta and the like (to the extent it’s currently possible).




.webp)
_.webp)
.webp)

.webp)

.webp)
.webp)
.webp)